

Agent Skillsが主要開発ツールの「共通言語」になった
Claude Agent Skillsの重要性が、また一段階上がりました。
これまでClaude Code専用だったAgent Skillsが、今やCursor、VS Code、GitHub、OpenCode、Amp、Letta、Gooseなど、主要な開発ツールすべてに対応可能となりました。
そしてこのタイミングで、Anthropicから公式のAgent Skills作成ガイドが公開されました。
これは単なるドキュメント更新ではありません。Agent SkillsがAIエージェント開発のオープンスタンダードとして確立されたことを意味します。
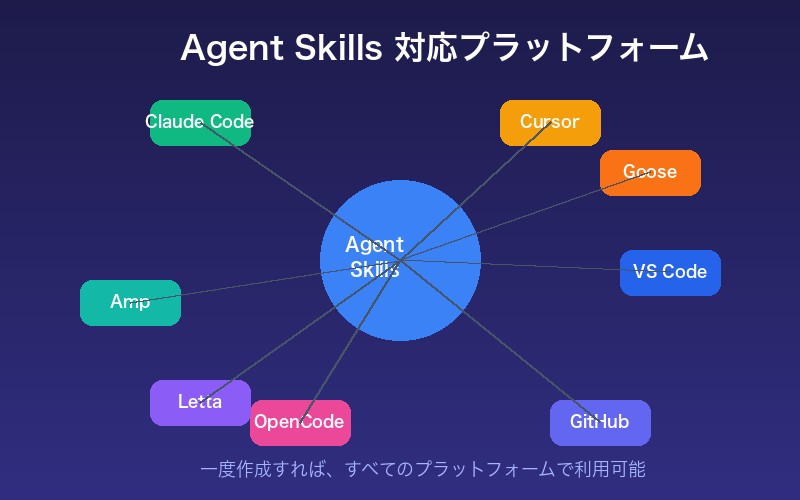
Agent Skillsとは何か:AIの「知識パック」
Agent Skillsを一言で説明すると、AIエージェントの能力を拡張する「知識パック」です。
公式ドキュメントの定義:
「Skillsとは、エージェントが発見・使用できる専門的な能力を提供する指示、スクリプト、リソースのフォルダです。これによりエージェントはより正確かつ効率的にタスクを実行できます」
従来のプロンプトとの違い
| 項目 | 従来のプロンプト | Agent Skills |
|---|---|---|
| 形式 | テキストのみ | フォルダ構造(指示+スクリプト+リソース) |
| 再利用性 | コピペが必要 | 一度作成すれば複数エージェントで利用可能 |
| 読み込み | 全文を常に読み込む | 必要な部分だけ段階的に読み込み |
| バージョン管理 | 困難 | Gitで管理可能 |
| クロスプラットフォーム | 非対応 | Cursor、GitHub、VS Code等で共通利用 |
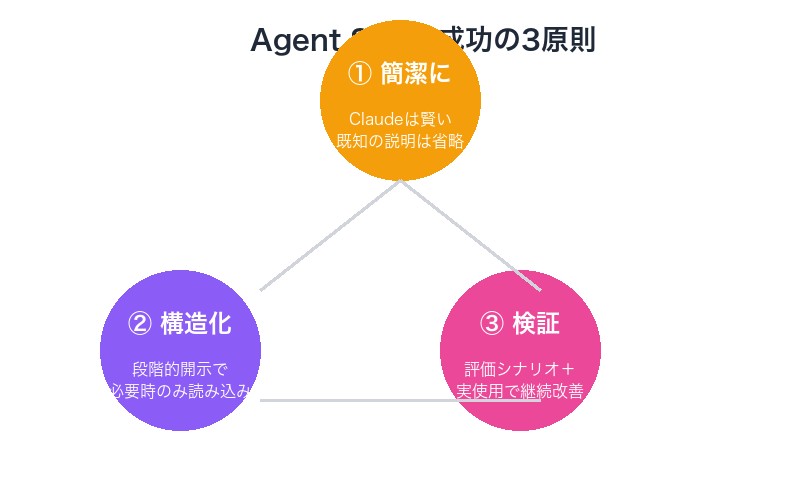
公式ガイドが示す「成功の3原則」
Anthropicの公式ガイドでは、効果的なSkill作成の3つの核心原則が示されています。
原則1:簡潔さが鍵
最も重要な原則は「Claudeは既に非常に賢い」という前提です。
公式ガイドより:
「Claudeが既に知っていることの説明は省略してください。各情報に対して問いかけましょう:『Claudeは本当にこの説明が必要か?』『これはトークンコストに見合う価値があるか?』」
悪い例(約150トークン):
PDF(Portable Document Format)ファイルは、テキスト、画像、 その他のコンテンツを含む一般的なファイル形式です。PDFからテキストを 抽出するにはライブラリが必要です。PDF処理用のライブラリは多数...
良い例(約50トークン):
## PDFテキスト抽出
pdfplumberを使用:
```python
import pdfplumber
with pdfplumber.open("file.pdf") as pdf:
text = pdf.pages[0].extract_text()
```
原則2:適切な自由度の設定
タスクの性質に応じて、指示の詳細度を調整します。
| 自由度 | 使用場面 | 例 |
|---|---|---|
| 高 | 複数アプローチが有効な場合 | コードレビュー、文章校正 |
| 中 | パターンあり+柔軟性が必要 | テンプレート生成、レポート作成 |
| 低 | 順序厳守が必要な場合 | DBマイグレーション、CI/CDパイプライン |
公式ガイドのたとえ:
「Claudeをロボットがパスを探索する姿と考えてください。両側が崖の狭い橋では具体的なガードレールが必要(低自由度)。障害物のない広い野原では一般的な方向だけ示して最適ルートを任せる(高自由度)」
原則3:実使用でのテストと検証
Skillsはモデルによって効果が異なります。使用予定のすべてのモデルでテストが必須です。
| モデル | テスト観点 |
|---|---|
| Claude Haiku | 十分なガイダンスが提供されているか? |
| Claude Sonnet | 明確で効率的か? |
| Claude Opus | 過剰な説明をしていないか? |
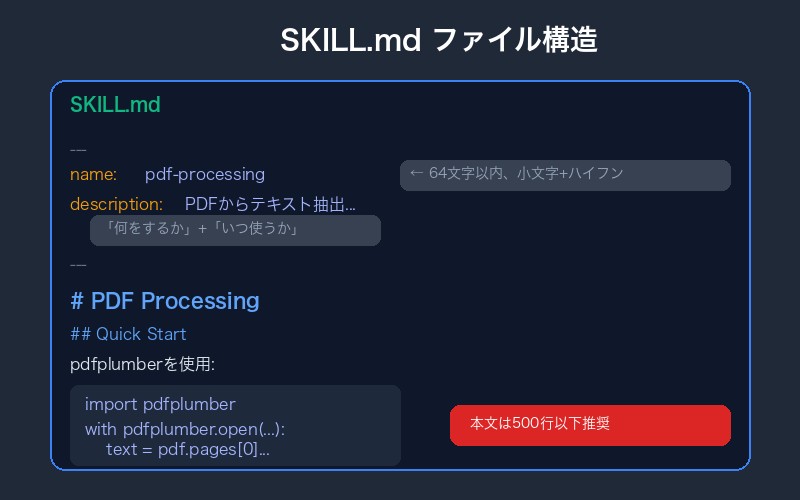
SKILL.mdの正しい書き方
Agent Skillsの中核となるのがSKILL.mdファイルです。
必須フィールド
--- name: pdf-processing description: PDFファイルからテキストと表を抽出し、フォームを埋め、ドキュメントを結合します。PDFファイルを扱う際や、ユーザーがPDF、フォーム、ドキュメント抽出について言及した際に使用します。 --- # PDF Processing ## クイックスタート ...
nameフィールドのルール
- 最大64文字
- 小文字、数字、ハイフンのみ使用可能
- XMLタグを含めない
- 予約語(「anthropic」「claude」)は使用禁止
良い命名例(動名詞形式推奨):
- processing-pdfs
- analyzing-spreadsheets
- managing-databases
- testing-code
避けるべき命名:
- helper, utils, tools(曖昧すぎる)
- documents, data, files(一般的すぎる)
- anthropic-helper, claude-tools(予約語を含む)
descriptionフィールドのルール
- 最大1024文字
- 何をするかといつ使うかを必ず含める
- 三人称で記述(「Processes…」「Extracts…」)
良い例:
description: Excelスプレッドシートを分析し、ピボットテーブルを作成し、チャートを生成します。Excelファイル、スプレッドシート、表形式データ、.xlsxファイルの分析時に使用します。
悪い例:
description: ドキュメントを処理します
段階的開示(Progressive Disclosure)パターン
SKILL.mdは目次のような役割を果たし、詳細な情報は必要に応じて別ファイルから読み込まれます。
推奨ディレクトリ構造
pdf/
├── SKILL.md # メイン指示(トリガー時に読み込み)
├── FORMS.md # フォーム入力ガイド(必要時に読み込み)
├── reference.md # APIリファレンス(必要時に読み込み)
├── examples.md # 使用例(必要時に読み込み)
└── scripts/
├── analyze_form.py # ユーティリティスクリプト(実行用)
├── fill_form.py # フォーム入力スクリプト
└── validate.py # バリデーションスクリプト
重要:参照は1階層まで
公式ガイドは深いネスト参照を避けるよう強く推奨しています。
悪い例(深すぎる):
SKILL.md → advanced.md → details.md → 実際の情報
良い例(1階層):
SKILL.md → advanced.md SKILL.md → reference.md SKILL.md → examples.md
本文は500行以下に
SKILL.mdの本文は500行以下を推奨。超える場合は別ファイルに分割します。
ワークフローとフィードバックループ
複雑なタスクには、チェックリスト付きワークフローを提供します。
ワークフロー例:PDFフォーム入力
## PDFフォーム入力ワークフロー このチェックリストをコピーして進捗を追跡: ``` タスク進捗: - [ ] Step 1: フォーム分析(analyze_form.py実行) - [ ] Step 2: フィールドマッピング作成(fields.json編集) - [ ] Step 3: マッピング検証(validate_fields.py実行) - [ ] Step 4: フォーム入力(fill_form.py実行) - [ ] Step 5: 出力検証(verify_output.py実行) ``` **Step 1: フォーム分析** 実行: `python scripts/analyze_form.py input.pdf` **Step 2: フィールドマッピング作成** `fields.json`を編集して各フィールドに値を追加 ...
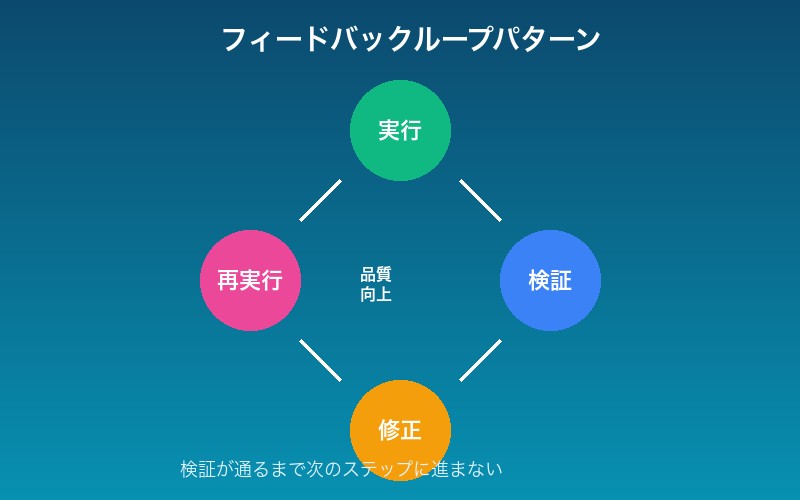
フィードバックループの実装
「実行→検証→修正→再実行」パターンが品質を大幅に向上させます。
1. `word/document.xml`を編集 2. **即座に検証**: `python ooxml/scripts/validate.py unpacked_dir/` 3. 検証失敗時: - エラーメッセージを確認 - XMLの問題を修正 - 再度検証を実行 4. **検証が通るまで進まない** 5. リビルド: `python ooxml/scripts/pack.py unpacked_dir/ output.docx`
絶対に避けるべきアンチパターン
公式ガイドで明確に禁止されているパターンがあります。
1. 時間依存情報
悪い例:
2025年8月以降は新APIを使用してください。 それ以前は旧APIを使用してください。
良い例:
## 現在の方法 v2 APIエンドポイントを使用: `api.example.com/v2/messages` ## 旧パターンレガシーv1 API(2025-08に非推奨化)
v1 APIは `api.example.com/v1/messages` を使用していました。
2. 用語の不統一
| 悪い例(混在) | 良い例(統一) |
|---|---|
| endpoint / URL / API route / path | 常に「API endpoint」 |
| field / box / element / control | 常に「field」 |
| extract / pull / get / retrieve | 常に「extract」 |
3. 選択肢の提示しすぎ
悪い例:
pypdf、pdfplumber、PyMuPDF、pdf2image、...のいずれかを使用できます
良い例:
テキスト抽出にはpdfplumberを使用: ```python import pdfplumber ``` スキャンPDFでOCRが必要な場合は、代わりにpdf2image + pytesseractを使用
4. Windowsスタイルのパス
- ✓ 正しい:
scripts/helper.py,reference/guide.md - ✗ 間違い:
scripts\helper.py,reference\guide.md
5. マジックナンバー(理由なき数値)
悪い例:
TIMEOUT = 47 # なぜ47? RETRIES = 5 # なぜ5?
良い例:
# HTTPリクエストは通常30秒以内に完了 # 遅い接続を考慮して長めに設定 REQUEST_TIMEOUT = 30 # 3回のリトライで信頼性と速度のバランスを確保 # ほとんどの間欠的障害は2回目で解決 MAX_RETRIES = 3
評価駆動開発:テストを先に作る
公式ガイドは「評価を先に作る」アプローチを強く推奨しています。
評価駆動開発のステップ
- ギャップの特定:Skillなしでタスクを実行し、失敗点を記録
- 評価の作成:最低3つのシナリオでテスト
- ベースライン確立:Skillなしのパフォーマンスを測定
- 最小限のSkill作成:ギャップを埋めるための最小限のコンテンツ
- 反復改善:評価を実行し、ベースラインと比較して改良
評価シナリオの例
{
"skills": ["pdf-processing"],
"query": "このPDFファイルからすべてのテキストを抽出してoutput.txtに保存してください",
"files": ["test-files/document.pdf"],
"expected_behavior": [
"適切なPDF処理ライブラリまたはコマンドラインツールを使用してPDFファイルを正常に読み込む",
"ドキュメントのすべてのページからテキストコンテンツを抽出する(ページの欠落なし)",
"抽出したテキストをoutput.txtというファイルに明確で読みやすい形式で保存する"
]
}
Claudeを使ったSkill開発ワークフロー
最も効果的なSkill開発は、Claude自身を使った反復的プロセスです。
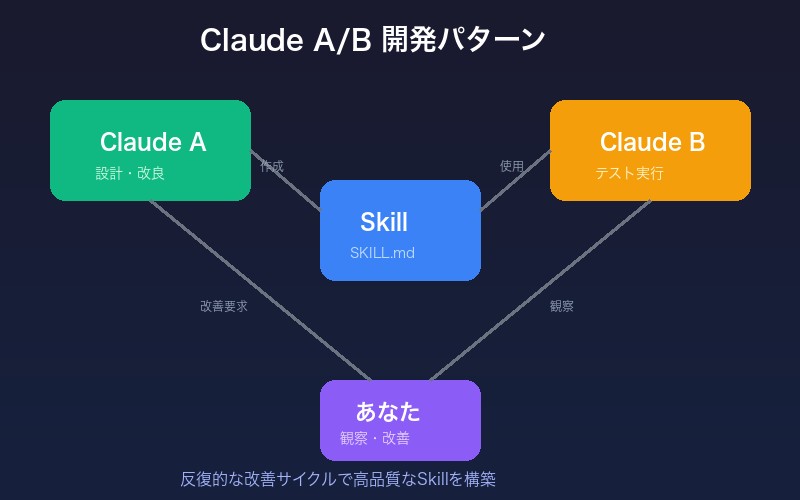
Claude A(作成)/ Claude B(実行)パターン
| 役割 | 担当 |
|---|---|
| Claude A | Skillの設計・改良を支援(作成者) |
| Claude B | Skillを使用して実タスクを実行(テスター) |
| あなた | ドメイン知識の提供、観察、フィードバック |
開発フロー
- Skillなしでタスク完了:Claude Aと通常のプロンプトで作業
- 再利用パターンの特定:繰り返し提供した情報を抽出
- Claude AにSkill作成を依頼:「このパターンをSkillにしてください」
- 簡潔さをレビュー:不要な説明を削除
- Claude Bでテスト:新しいインスタンスでSkillを使用
- 観察に基づいて改良:Claude Aに具体的な問題点を伝えて改善
agentskills.io:Skillの共有プラットフォーム
Agent Skillsのエコシステムを支えるのがagentskills.ioです。
プラットフォームの特徴
- オープンフォーマット:Anthropicが開発し、オープンスタンダードとして公開
- クロスプラットフォーム:Cursor、VS Code、GitHub、Claude Codeなどで共通利用
- バージョン管理:Git対応のポータブルなフォーマット
- コミュニティ貢献:Skillの共有・発見が可能
リソース一覧
| リソース | 内容 |
|---|---|
| Specification | SKILL.mdフォーマットの仕様書 |
| Integration Guide | エージェント開発者向けガイド |
| Example Skills | GitHubのサンプルSkillリポジトリ |
| Reference Library | バリデーション・XML生成ライブラリ |
公開前チェックリスト
Skillを公開する前に、以下を確認してください。
コア品質
- ☐ descriptionに使用タイミングを含む
- ☐ descriptionに「何をするか」と「いつ使うか」の両方を含む
- ☐ SKILL.md本文が500行以下
- ☐ 追加詳細は別ファイルに分離(必要な場合)
- ☐ 時間依存情報なし(または「旧パターン」セクションに記載)
- ☐ 用語が一貫している
- ☐ 具体例が含まれている
- ☐ ファイル参照は1階層まで
- ☐ 段階的開示を適切に使用
- ☐ ワークフローに明確なステップがある
コード・スクリプト
- ☐ スクリプトは問題を解決(Claudeに丸投げしない)
- ☐ エラー処理が明示的で有用
- ☐ マジックナンバーなし(すべての値に理由)
- ☐ 必要なパッケージが明記されている
- ☐ Windowsパスなし(すべてスラッシュ)
- ☐ 検証・確認ステップが含まれている
テスト
- ☐ 最低3つの評価シナリオを作成
- ☐ Haiku、Sonnet、Opusでテスト済み
- ☐ 実使用シナリオでテスト済み
- ☐ チームフィードバックを反映(該当する場合)
まとめ:Agent Skillsで何が変わるか
Claude Agent Skillsの公式ガイド公開と主要プラットフォーム対応が意味すること:
- 標準化:AIエージェント開発の共通フォーマットが確立
- クロスプラットフォーム:Cursor、GitHub、VS Codeなどで同じSkillを利用可能
- 再利用性:一度作成したSkillを複数のエージェントで活用
- 効率化:段階的開示でコンテキストウィンドウを節約
- 品質向上:評価駆動開発とフィードバックループで継続改善
これからAIエージェント開発を始める方も、既にプロンプトエンジニアリングを行っている方も、Agent Skillsの習得は必須のスキルとなるでしょう。
公式ガイドを一読し、まずは小さなSkillから作成してみることをお勧めします。
関連リンク:
関連記事:
コメント