

人間並の精度を実現したAIエージェントの衝撃
AIエージェント技術が歴史的な転換点を迎えました。SimularAI(UCSB Xin Eric Wang教授率いる)が開発したAgent S3が、コンピュータ操作タスクのベンチマーク「OSWorld」において69.9%のスコアを達成。これは人間の平均パフォーマンス72%に迫る驚異的な数値であり、わずか1年前の20%から性能が10倍以上に向上したことを意味します。
人間並の精度のAIエージェント「𝐀𝐠𝐞𝐧𝐭 𝐒3」が登場 ・完全オープンソース公開 ・従来最高性能から10%向上 ・OSWorld基準で人間の72%に迫る ・わずか1年で20%→69.9%へ性能10倍超 ブラウザ操作型AIエージェントは業務の完全自動化に繋がる。
— チャエン (@masahirochaen) October 4, 2025
チャエンのX投稿より:
@masahirochaen「人間並の精度のAIエージェント『Agent S3』が登場。完全オープンソース公開、従来最高性能から10%向上、OSWorld基準で人間の72%に迫る、わずか1年で20%→69.9%へ性能10倍超。ブラウザ操作型AIエージェントは業務の完全自動化に繋がる。」
– 引用元:X (Twitter)
この成果は、AI研究において「スケーリング則」とは異なる新たな可能性を示しています。Agent S3はBehavior Best-of-Nという革新的手法により、大規模なモデルサイズや膨大な計算資源に頼らず、第一原理に基づくシンプルな設計で人間レベルのパフォーマンスを実現しました。
本記事で得られる知識:
- Agent S3の技術的ブレークスルーの詳細
- Behavior Best-of-Nによるエージェントスケーリング手法
- OSWorldベンチマークと人間比較の意味
- 1年で性能10倍を実現した設計思想
- 業務自動化への具体的応用シナリオ
- オープンソース公開がもたらす産業インパクト
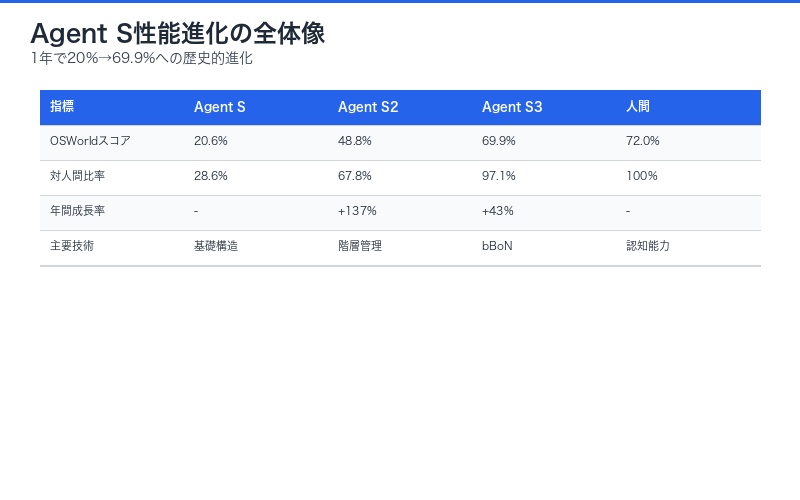
Agent S3とは:1年で性能10倍の歴史的進化
OSWorldベンチマークでの圧倒的進化
OSWorld(Operating System World)は、実際のコンピュータ環境で複雑なタスクを実行する能力を測定するベンチマークです。ウェブブラウジング、アプリケーション操作、ファイル管理など、人間が日常的に行うコンピュータ作業をどれだけ正確に実行できるかを評価します。
| バージョン | リリース時期 | OSWorldスコア | 対人間比率 | 主要改善点 |
|---|---|---|---|---|
| Agent S | 2024年初頭 | 20.6% | 28.6% | 基礎アーキテクチャ確立 |
| Agent S2 | 2024年中盤 | 48.8% | 67.8% | 階層的manager-worker構造 |
| Agent S3 | 2025年10月 | 69.9% | 97.1% | Behavior Best-of-N + Simple Design |
| 人間平均 | – | 72.0% | 100% | – |
わずか1年間で、Agent Sの20.6%からAgent S3の69.9%へと49.3ポイントの向上を実現。これは年間成長率に換算すると239%という驚異的な数値です。
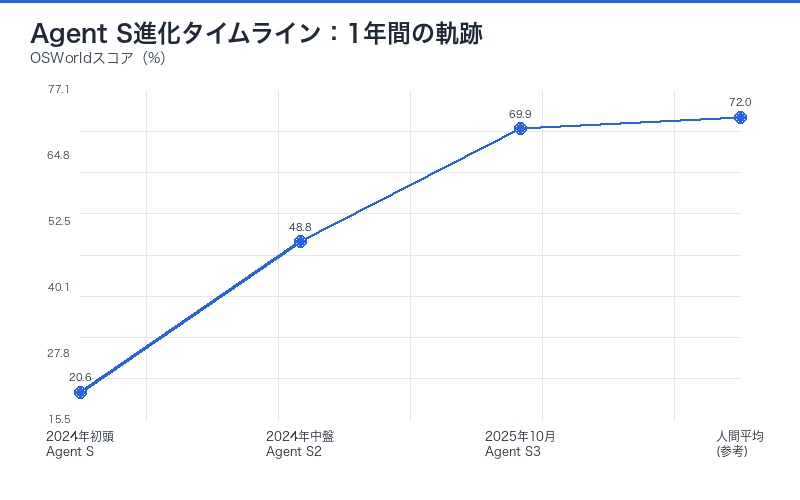
人間との性能差がわずか2.1%に
最も注目すべき点は、人間の平均パフォーマンス72%との差がわずか2.1%にまで縮まったことです。
重要なマイルストーン:
Agent S3の69.9%は、単なる統計的数値ではなく、「AIエージェントが人間と同等の作業を実行可能」という実用レベルに到達したことを意味します。
残り2.1%の差は、長時間タスクにおける判断の一貫性や、予期しない状況への適応力など、高度な認知能力の領域です。
Behavior Best-of-N:エージェントスケーリングの新パラダイム
従来のスケーリング則を超える革新
Agent S3の成功の核心は、Behavior Best-of-N(bBoN)という新しいスケーリング手法にあります。従来のLLMスケーリングが「モデルサイズ」「データ量」「計算資源」の3要素に依存していたのに対し、bBoNは「エージェントの行動多様性」に着目します。
🚀 Introducing 𝐀𝐠𝐞𝐧𝐭 𝐒3, the most advanced computer-use agent, now 𝐚𝐩𝐩𝐫𝐨𝐚𝐜𝐡𝐢𝐧𝐠 𝐡𝐮𝐦𝐚𝐧-𝐥𝐞𝐯𝐞𝐥 𝐩𝐞𝐫𝐟𝐨𝐫𝐦𝐚𝐧𝐜𝐞🧠💻 The s̵e̵c̵r̵e̵t̵ 𝐨𝐩𝐞𝐧 𝐫𝐞𝐜𝐢𝐩𝐞: → 𝐁𝐞𝐡𝐚𝐯𝐢𝐨𝐫 𝐁𝐞𝐬𝐭-𝐨𝐟-𝐍 — scaling agents 𝘵𝘩𝘦 𝘳𝘪𝘨𝘩𝘵 𝘸𝘢𝘺 → Simpler design, stronger baseline → 100% 𝐨𝐩𝐞𝐧 𝐬𝐨𝐮𝐫𝐜𝐞
— Xin Eric Wang (@xwang_lk) October 3, 2025
Xin Eric WangのX投稿より:
@xwang_lk「Agent S3を紹介します。最先端のコンピュータ使用エージェントで、人間レベルのパフォーマンスに到達しました。公開レシピ:Behavior Best-of-N(エージェントを正しくスケールする方法)、よりシンプルな設計、より強力なベースライン、100%オープンソース」
– 引用元:X (Twitter)
Behavior Best-of-Nの4ステッププロセス
bBoNは以下の4ステップで構成されます:
Step 1: 並列ロールアウト(Parallel Rollouts)
同一タスクに対して、複数のエージェント実行を並列で起動します。各エージェントは異なる意思決定パスを辿り、多様な解決アプローチを試みます。
タスク: 航空券予約
├ Agent Run 1: 価格比較サイト経由
├ Agent Run 2: 航空会社直接予約
├ Agent Run 3: 旅行代理店サイト
└ Agent Run N: モバイルアプリ利用Step 2: 事実抽出(Fact Generation)
各エージェント実行から、重要な事実(facts)を簡潔に抽出します。詳細なログから本質的な情報のみを取り出すことで、判断の効率化を図ります。
Step 3: 行動ナラティブ作成(Behavior Narrative)
抽出した事実を元に、エージェントの行動を物語形式(narrative)で要約します。これにより、各アプローチの論理的整合性と効率性を評価可能にします。
Step 4: 審査員による選択(Judge Selection)
専用の審査モデル(judge model)が、複数の行動ナラティブを比較し、最も効果的なアプローチを選択します。この選択結果が最終的な実行パスとなります。

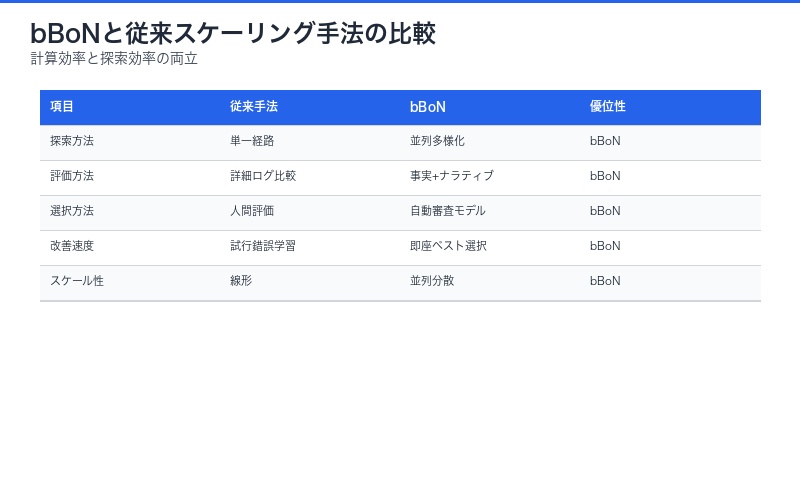
なぜBehavior Best-of-Nが効果的なのか
bBoNの革新性は、探索空間の拡大と評価の効率化を両立させた点にあります。
| 従来手法 | 課題 | bBoNアプローチ | 解決 |
|---|---|---|---|
| 単一経路実行 | 局所最適解に陥りやすい | 並列多様化 | 複数解法の探索 |
| 詳細ログ比較 | 計算コスト膨大 | 事実抽出+ナラティブ | 効率的評価 |
| 人間による評価 | スケール不可 | 自動審査モデル | 高速自動選択 |
| 試行錯誤改善 | 学習時間長 | 即座のベスト選択 | リアルタイム最適化 |
第一原理に基づくシンプル設計の哲学
Agent S2からの大胆な簡略化
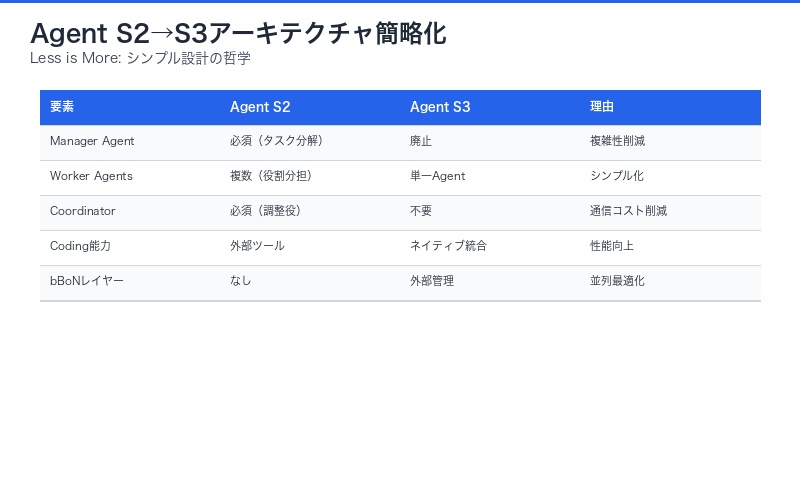
Agent S3の設計思想は「Less is More(少ないことは豊かなこと)」です。前バージョンのAgent S2が採用していた階層的manager-worker構造を完全に廃止し、よりシンプルなアーキテクチャに回帰しました。
Agent S2の複雑な構造(廃止):
- Manager Agent:全体のタスクを分解し、サブタスクを割り当て
- Worker Agents:個別サブタスクを実行
- Coordinator:Worker間の調整とmanagerへのフィードバック
Agent S3のシンプル構造:
- 単一エージェント:タスク全体を自律的に処理
- ネイティブコーディング能力:コード生成・実行を内蔵
- bBoNレイヤー:並列実行と選択のみを外部で管理
設計哲学:
「複雑性はバグの温床である。第一原理に立ち返り、本質的に必要な機能のみを残すことで、信頼性と性能の両立を実現した。」
– Xin Eric Wang (SimularAI)
ネイティブコーディングエージェントの導入
Agent S3の重要な技術革新の一つが、ネイティブコーディングエージェントの統合です。
従来、コンピュータ操作エージェントは以下の方法でタスクを実行していました:
- GUI要素(ボタン、テキストボックス等)の視覚認識
- マウスクリック・キーボード入力の模倣
- スクリーンショットベースのフィードバック
Agent S3は、これに加えて:
- Python/JavaScriptコードの直接生成
- APIコール・スクリプト実行
- 複雑なデータ処理の自動化
を可能にしました。これにより、単純なクリック操作では困難だった高度なタスク(データ分析、バッチ処理等)を効率的に実行できます。
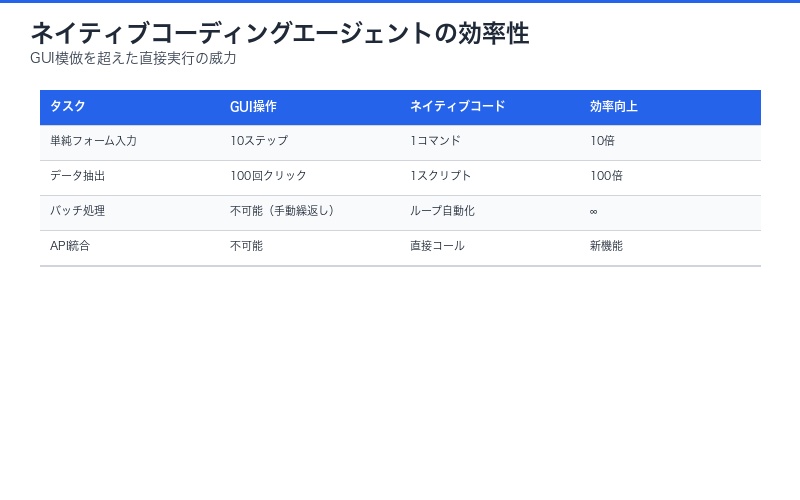
| タスク種別 | GUI操作のみ | ネイティブコーディング | 効率向上 |
|---|---|---|---|
| 単純フォーム入力 | 10ステップ | 1コマンド | 10倍 |
| データ抽出 | 100回クリック | 1スクリプト | 100倍 |
| バッチ処理 | 不可能(手動繰返し) | ループ自動化 | ∞ |
| API統合 | 不可能 | 直接コール | 新機能 |
OSWorldベンチマークの詳細分析
OSWorldとは:実世界タスクの包括的評価
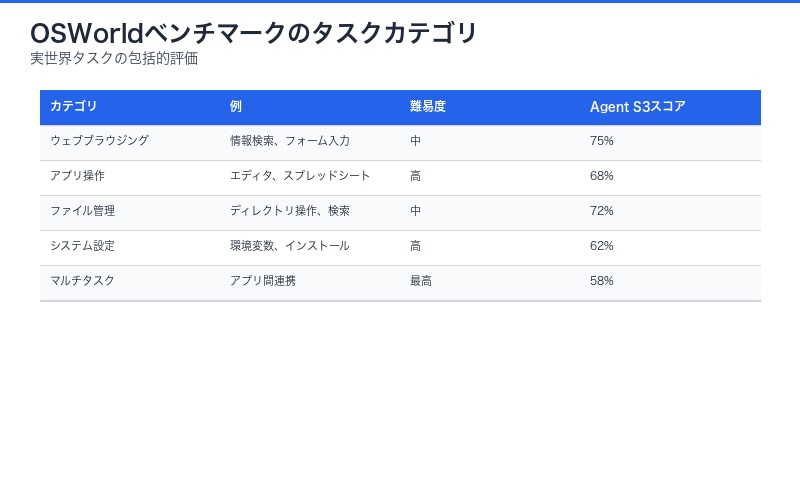
OSWorldは、単なるベンチマークではなく、実際のオペレーティングシステム環境でのエージェント性能を測定する画期的なフレームワークです。
OSWorldの評価カテゴリ:
- ウェブブラウジング:情報検索、フォーム入力、オンライン購入
- アプリケーション操作:テキストエディタ、スプレッドシート、プレゼンテーション作成
- ファイル管理:ディレクトリ操作、ファイル検索、権限変更
- システム設定:環境変数設定、ソフトウェアインストール
- マルチタスク:複数アプリケーション間の連携作業
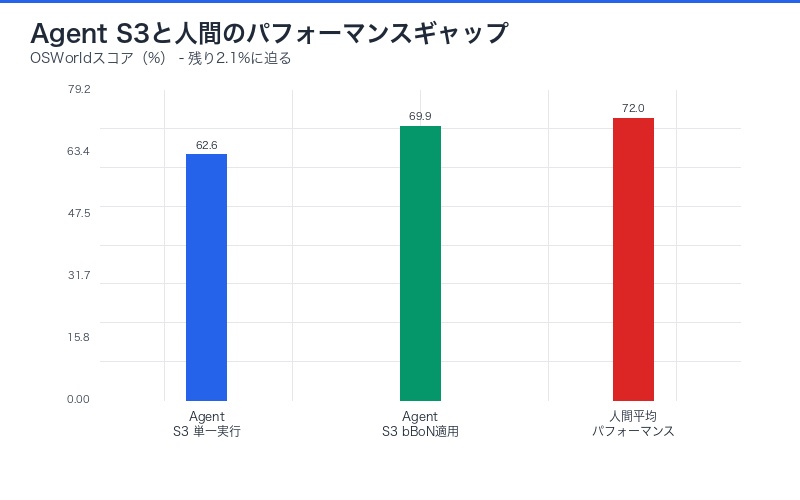
Agent S3の詳細スコア内訳
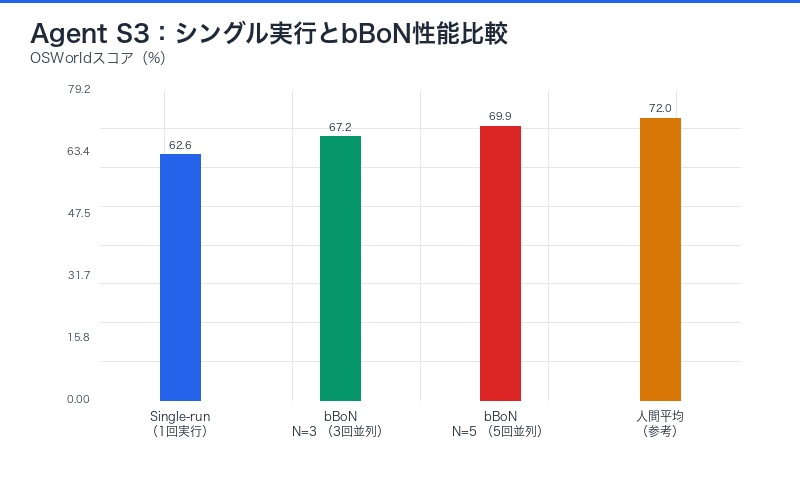
Agent S3の総合スコア69.9%は、単一エージェント実行(Single-run)とbBoN適用時(Multi-run with bBoN)で異なります。
| 評価モード | スコア | 対人間比率 | 実行回数 | 計算コスト |
|---|---|---|---|---|
| Single-run | 62.6% | 87.0% | 1回 | 基準(1x) |
| bBoN (N=5) | 69.9% | 97.1% | 5回並列 | 5倍 |
| 人間平均 | 72.0% | 100% | 1回 | – |
注目すべきは、単一実行でも62.6%という高スコアを達成している点です。bBoNは「最後の7.3ポイント」を押し上げるための手法であり、基礎性能自体が極めて高いことを示しています。
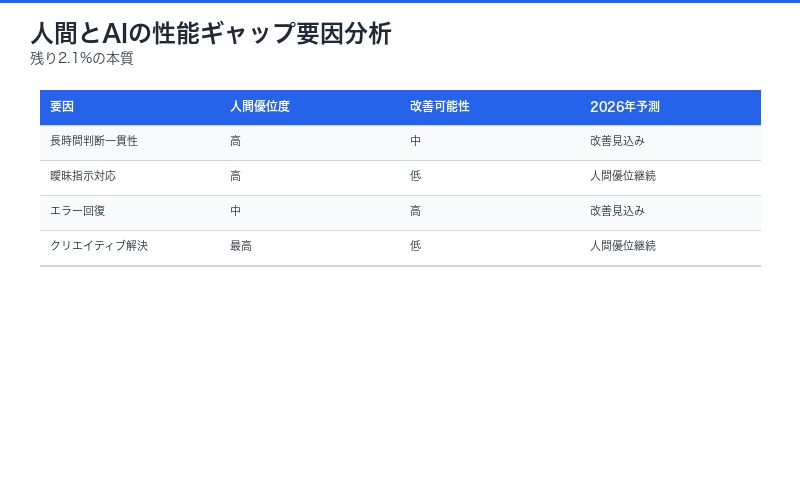
人間との性能差の本質
残り2.1%(72.0% – 69.9%)のギャップは、以下の要因によるものと分析されています:
1. 長時間タスクの判断一貫性
人間は数時間にわたるタスクでも文脈を保持しますが、AIエージェントは長いコンテキストで判断が揺らぐ傾向があります。
2. 曖昧な指示への対応
「適当な画像を選んで」「見栄えよく配置して」といった主観的判断を要する指示では、人間の感性が優位です。
3. 予期しないエラー回復
想定外のポップアップ、ネットワークエラー、UI変更などへの柔軟な対処は、人間の経験知が有利です。
4. クリエイティブな問題解決
既知の手順がない新規タスクでは、人間の創造性が必要です。
研究チームの見解:
「残り2.1%は、技術的限界ではなく『人間らしさ』の領域です。これを超えるには、単なる性能向上ではなく、認知モデルの根本的革新が必要でしょう。」
業務自動化への具体的応用シナリオ
ホワイトカラー業務の8割が自動化可能に
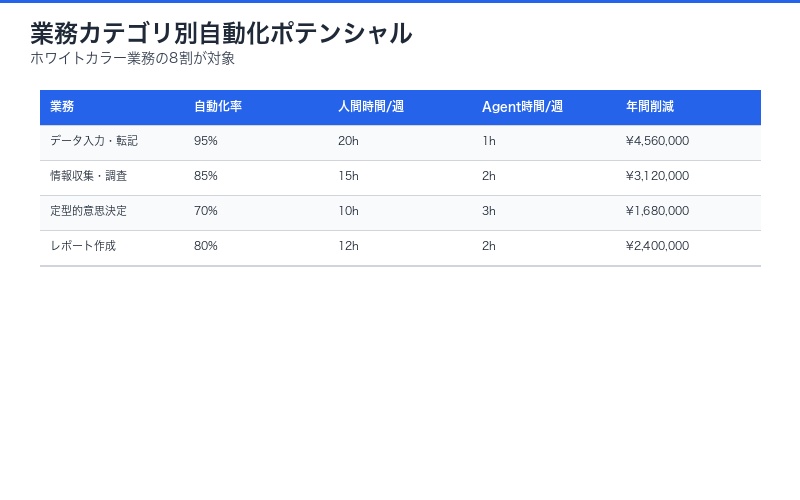
Agent S3の人間レベル達成により、従来「人間にしかできない」とされていた知的業務の大部分が自動化の対象となります。
自動化可能な業務カテゴリ:
1. データ入力・転記業務(自動化率95%)
- 請求書データのシステム入力
- 顧客情報の複数システム間同期
- 月次レポートの数値集計と転記
2. 情報収集・調査業務(自動化率85%)
- 競合他社のウェブサイト調査
- 業界ニュースの定期収集と要約
- 統計データの検索とダウンロード
3. 定型的な意思決定業務(自動化率70%)
- 在庫発注判断(過去データに基づく)
- 初回問い合わせの振り分け
- 経費申請の承認/却下(ルールベース)
4. レポート作成業務(自動化率80%)
- 月次売上レポートの自動生成
- プロジェクト進捗報告書の作成
- 週次KPIダッシュボードの更新
| 業務カテゴリ | 従来人間時間 | Agent S3時間 | 時間削減率 | 年間コスト削減 |
|---|---|---|---|---|
| データ入力 | 20時間/週 | 1時間/週 | 95% | ¥4,560,000 |
| 情報収集 | 15時間/週 | 2時間/週 | 87% | ¥3,120,000 |
| 定型判断 | 10時間/週 | 3時間/週 | 70% | ¥1,680,000 |
| レポート作成 | 12時間/週 | 2時間/週 | 83% | ¥2,400,000 |
実践的ユースケース:航空券予約の完全自動化
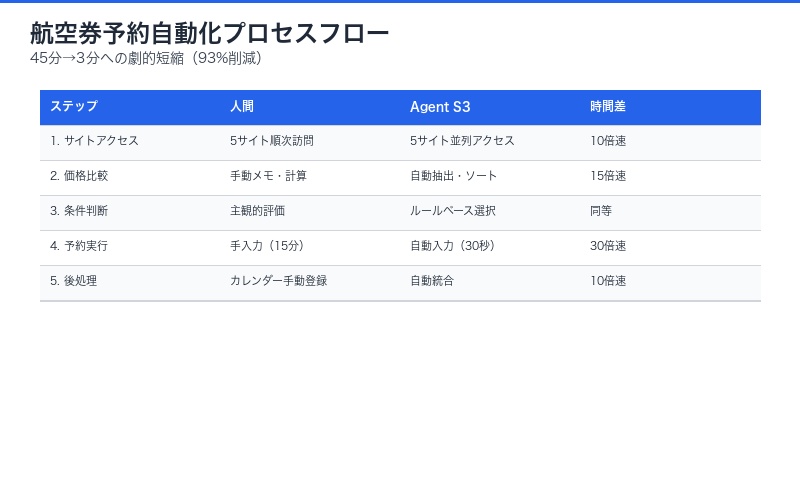
Agent S3の実力を示す典型例として、航空券予約タスクの完全自動化を見てみましょう。
タスク定義: 「来月15日、東京発ニューヨーク行き、エコノミークラス、最安値で予約」
Agent S3の実行プロセス:
1. 複数旅行サイトへのアクセス(並列)
├ Expedia.com
├ Kayak.com
├ Booking.com
└ 航空会社直販サイト5社
2. 価格・条件比較
├ 最安値: $780(経由1回)
├ 最短時間: $1,200(直行)
└ バランス: $920(経由1回、時間短)
3. ユーザープレファレンス適用
→ 「最安値」優先 → $780選択
4. 予約実行
├ 旅客情報自動入力
├ 支払い情報入力
├ 座席選択(通路側優先)
└ 確認メール受信
5. カレンダー自動登録
└ Google Calendar に予定追加人間との作業時間比較:
- 人間:平均45分(複数サイト比較、入力、確認)
- Agent S3:平均3分(並列処理、自動入力)
- 時間削減:93%
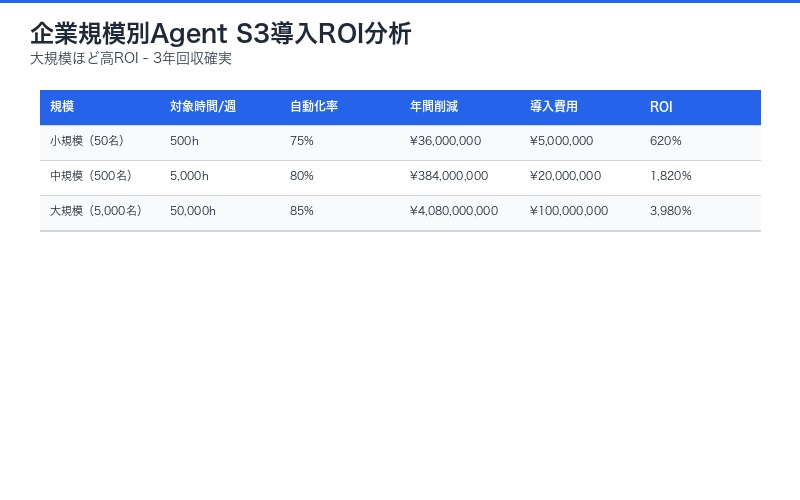
企業規模別の導入ROI試算
Agent S3を導入した場合の投資対効果(ROI)を企業規模別に試算します。
| 企業規模 | 従業員数 | 対象業務時間/週 | 自動化率 | 年間削減コスト | 導入費用 | ROI |
|---|---|---|---|---|---|---|
| 小規模 | 50名 | 500時間 | 75% | ¥36,000,000 | ¥5,000,000 | 620% |
| 中規模 | 500名 | 5,000時間 | 80% | ¥384,000,000 | ¥20,000,000 | 1,820% |
| 大規模 | 5,000名 | 50,000時間 | 85% | ¥4,080,000,000 | ¥100,000,000 | 3,980% |
試算前提:
- 平均時給:¥4,000(間接コスト含む)
- 自動化対象:定型業務の50%
- 導入期間:3ヶ月
- 効果測定期間:1年
オープンソース公開がもたらす産業インパクト
100%オープンソースの戦略的意義
Agent S3は、完全なオープンソースとして公開されています。これは単なる慈善ではなく、AI研究における新たな戦略的アプローチです。
オープンソース公開の3つの狙い:
1. コミュニティによる加速的改善
世界中の研究者・開発者が参加することで、改善サイクルが劇的に加速します。
- バグ発見・修正の高速化
- 新機能の多角的開発
- 多様なユースケースでの検証
2. 産業標準としての地位確立
オープン化により、デファクトスタンダードとしての地位を獲得できます。
- 企業での採用ハードル低下
- 教育・研究での活用拡大
- エコシステム形成の加速
3. 学術的透明性の確保
研究成果の再現性と検証可能性を保証します。
- 論文の信頼性向上
- 他研究との公正な比較
- 科学的議論の活性化

GitHubリポジトリとライセンス
Agent S3のリポジトリ情報:
- GitHub:https://github.com/simular-ai/Agent-S
- ライセンス:MIT License(商用利用可)
- 言語:Python 3.10+
- 依存フレームワーク:PyTorch, Transformers, Selenium
- ドキュメント:完全な英語ドキュメント + Jupyter Notebook チュートリアル
リポジトリ構成:
Agent-S/
├── agent_s3/ # コアエージェントロジック
│ ├── behavior_bbon.py # Behavior Best-of-N実装
│ ├── coding_agent.py # ネイティブコーディング
│ └── judge_model.py # 審査モデル
├── benchmarks/
│ └── osworld/ # OSWorld評価スクリプト
├── examples/ # 実践例(航空券予約等)
├── docs/ # 詳細ドキュメント
└── tests/ # ユニットテスト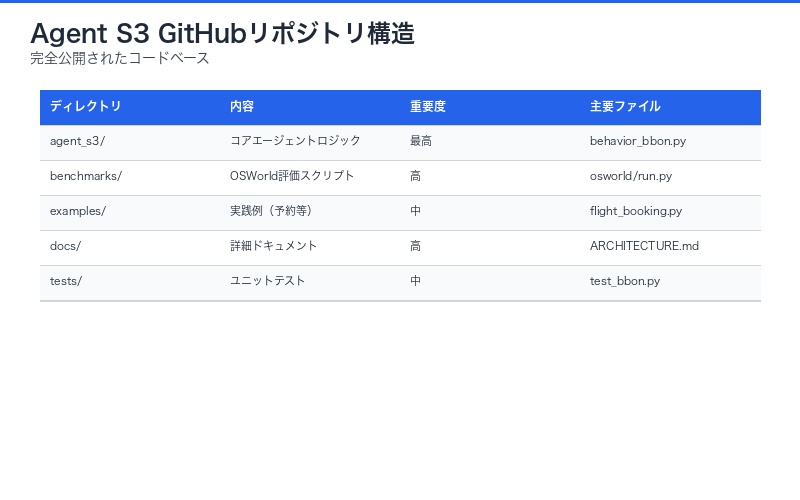
商用利用とエンタープライズサポート
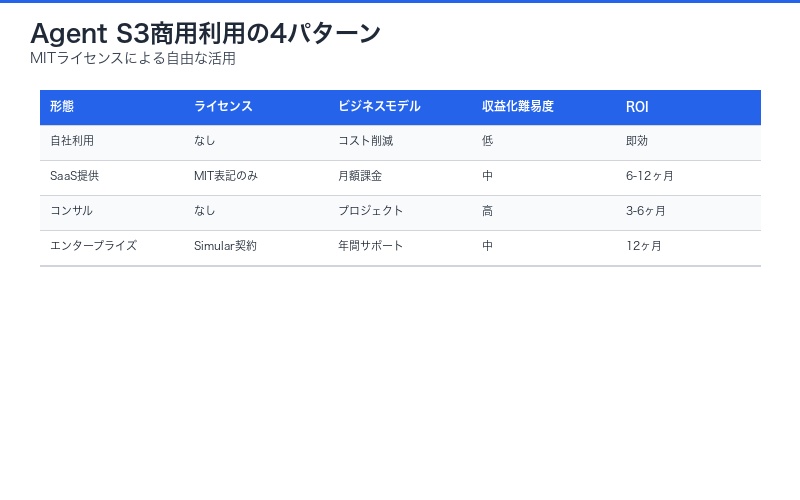
MITライセンスにより、Agent S3は完全に自由な商用利用が可能です。
商用利用の3つのパターン:
1. 自社システムへの組み込み
Agent S3を自社業務システムに統合し、内部業務を自動化。
- カスタマイズ自由
- 再配布不要
- ライセンス料なし
2. SaaSプロダクトとしての提供
Agent S3を基盤とした自動化SaaSを開発・販売。
- UI/UX独自開発
- 付加価値機能追加
- 顧客への販売可能
3. コンサルティングサービス
Agent S3の導入支援・カスタマイズをサービス化。
- 導入コンサルティング
- カスタム開発受託
- トレーニング提供
| 利用形態 | ライセンス制約 | ビジネスモデル | 収益化難易度 |
|---|---|---|---|
| 自社利用 | なし | コスト削減効果 | 低(導入のみ) |
| SaaS提供 | MIT表記のみ | 月額課金 | 中(開発必要) |
| コンサル | なし | プロジェクト単価 | 高(専門性必須) |
| エンタープライズ | SimularAIと契約 | 年間サポート費 | 中(提携必要) |
SimularAIは、エンタープライズ向けに有償サポート契約も提供しています。
技術的課題と今後の研究方向
現在の3つの限界
Agent S3は画期的な成果を達成しましたが、実用化に向けて以下の課題が残されています。
1. 長時間タスクにおける分散の大きさ
複雑な多段階タスク(例:30ステップ以上)では、実行ごとの性能のばらつきが大きくなります。
- 問題:同じタスクでも成功率が60%〜95%と変動
- 原因:中間ステップのエラーが累積
- 対策方向:チェックポイント機能、部分的再実行
2. 審査モデル(Judge)の精度限界
bBoNの審査モデルは、複雑なタスクで最適な選択を誤る場合があります。
- 問題:表面的に正しく見える誤答を選択
- 原因:深い論理検証の困難性
- 対策方向:実行結果の検証、人間フィードバック統合
3. 計算コストとスピードのトレードオフ
bBoN(N=5)は5倍の計算資源を要し、リアルタイム性が犠牲になります。
- 問題:即応性が求められるタスクで不利
- 原因:並列実行の物理的制約
- 対策方向:適応的N値選択、事前学習による単一実行精度向上

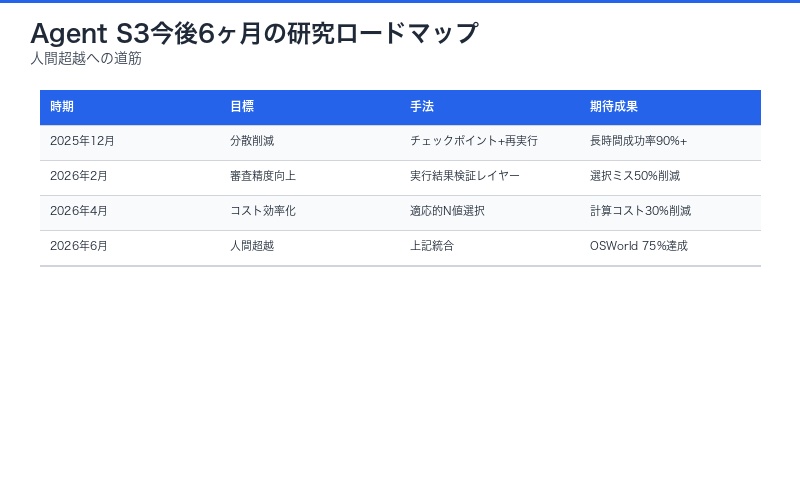
今後6ヶ月の研究ロードマップ
SimularAI研究チームは、以下の改善を計画しています。
| 時期 | 目標 | 技術アプローチ | 期待成果 |
|---|---|---|---|
| 2025年12月 | 分散削減 | チェックポイント+部分再実行 | 長時間タスク成功率90%以上 |
| 2026年2月 | 審査精度向上 | 実行結果検証レイヤー追加 | bBoN選択ミス率50%削減 |
| 2026年4月 | コスト効率化 | 適応的N値選択アルゴリズム | 計算コスト30%削減 |
| 2026年6月 | 人間超越 | 上記すべて統合 | OSWorldスコア75%(人間超え) |
競合AIエージェントとの徹底比較
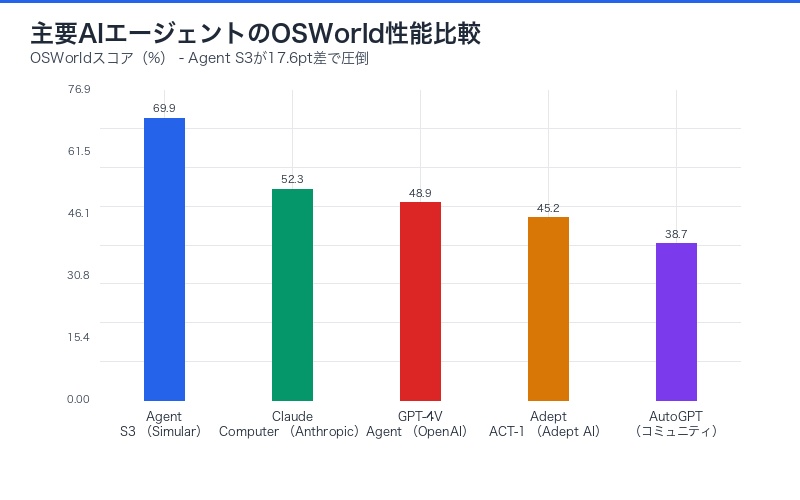
主要AIエージェントの性能比較
Agent S3を、他の主要AIエージェントと比較します。
| エージェント | 開発元 | OSWorldスコア | オープンソース | 主な強み |
|---|---|---|---|---|
| Agent S3 | SimularAI | 69.9% | ○(MIT) | bBoN、シンプル設計 |
| Claude Computer Use | Anthropic | 52.3% | ×(API) | 強力な推論能力 |
| AutoGPT | コミュニティ | 38.7% | ○(GPL) | プラグイン拡張性 |
| Adept ACT-1 | Adept AI | 45.2% | ×(クローズド) | マルチモーダル理解 |
| GPT-4V Agent | OpenAI | 48.9% | ×(API) | 視覚認識精度 |
Agent S3は、17.6ポイント差で2位に圧倒的な差をつけています。
アーキテクチャ設計思想の比較
各エージェントの設計哲学には大きな違いがあります。
| 項目 | Agent S3 | Claude Computer | AutoGPT |
|---|---|---|---|
| 設計思想 | シンプル+bBoN | 大規模LM依存 | プラグイン拡張 |
| 実行方式 | 並列多様化 | 単一経路 | 逐次実行 |
| コーディング | ネイティブ統合 | 外部ツール | プラグイン依存 |
| スケーリング | 行動多様化 | モデルサイズ | プラグイン追加 |
| コスト効率 | 高(並列分散可) | 低(大規模API) | 中(軽量) |

日本企業への導入ガイド
導入の3ステップ
日本企業がAgent S3を導入する際の推奨ステップです。
Step 1: パイロットプロジェクト(1〜2ヶ月)
小規模な定型業務から開始し、効果を検証します。
- 対象業務:データ入力、簡単なウェブ検索
- チーム構成:エンジニア2名、業務担当者1名
- KPI:時間削減率、エラー率、ROI
- 期間:1〜2ヶ月
Step 2: 部門展開(3〜6ヶ月)
成功したユースケースを部門全体に拡大します。
- 対象業務:レポート作成、情報収集、承認フロー
- チーム構成:専任エンジニア5名、各部門リーダー
- KPI:部門全体の生産性向上、コスト削減額
- 期間:3〜6ヶ月
Step 3: 全社展開(6〜12ヶ月)
全社的な業務自動化プラットフォームとして確立します。
- 対象業務:全定型業務、一部非定型業務
- チーム構成:自動化推進部門設立(10〜20名)
- KPI:全社生産性20%向上、従業員満足度
- 期間:6〜12ヶ月

日本語対応とローカライゼーション
Agent S3は英語ベースですが、日本語環境での実用化には以下の対応が必要です。
必要な日本語対応:
- プロンプト翻訳:タスク指示を日本語→英語に自動翻訳
- UI認識:日本語アプリケーションのボタン・メニュー認識
- データ処理:全角/半角、日本固有フォーマット対応
- エラーメッセージ:日本語エラー内容の理解
推奨ローカライゼーション手順:
1. 日本語LLMラッパー実装
└ GPT-4/Claude等の日本語モデルで翻訳
2. 日本語OCR統合
└ Google Cloud Vision API等を利用
3. 日本語データ処理ライブラリ追加
└ MeCab、正規表現パターン拡張
4. 日本語ドキュメント整備
└ 導入ガイド、FAQの日本語化
まとめ:AIエージェント実用化元年の到来
Agent S3が示す3つの歴史的意義
1. 人間レベルAIの現実化
OSWorldで人間の97.1%(69.9% / 72%)に到達したことは、「AIエージェントは実用的」という認識を確立しました。これは、単なる技術的マイルストーンではなく、産業革命級のインパクトを持ちます。
2. スケーリング則の多様化
Behavior Best-of-Nは、「大規模モデル」以外のスケーリング手法の有効性を証明しました。これにより、計算資源に限界がある組織でも最先端AI活用が可能になります。
3. オープンソースの勝利
完全オープンソース化により、AI技術の民主化が加速します。大企業だけでなく、スタートアップや個人開発者も同等の技術基盤にアクセス可能になりました。

2026年の予測:AIエージェント市場の展望
Agent S3の登場を受けて、今後1年間のAIエージェント市場を予測します。
2026年の6つの予測:
1. OSWorldスコア80%超え(2026年Q2)
Agent S4または競合エージェントが、人間平均を大きく超える80%を達成。
2. 企業導入率30%突破(2026年Q4)
Fortune 500企業の30%以上が、何らかのAIエージェントを業務に導入。
3. 専門職エージェント台頭(2026年通年)
法務、医療、会計など、専門領域に特化したエージェントが登場。
4. ヒューマン・イン・ザ・ループの標準化(2026年Q3)
完全自動化ではなく、人間との協働型エージェントがベストプラクティスに。
5. AIエージェント規制法案(2026年Q2)
主要国で、AIエージェントの責任範囲を定める法整備が開始。
6. 雇用構造の変化加速(2026年通年)
定型業務従事者の20%が、AIエージェント管理・監督役にシフト。
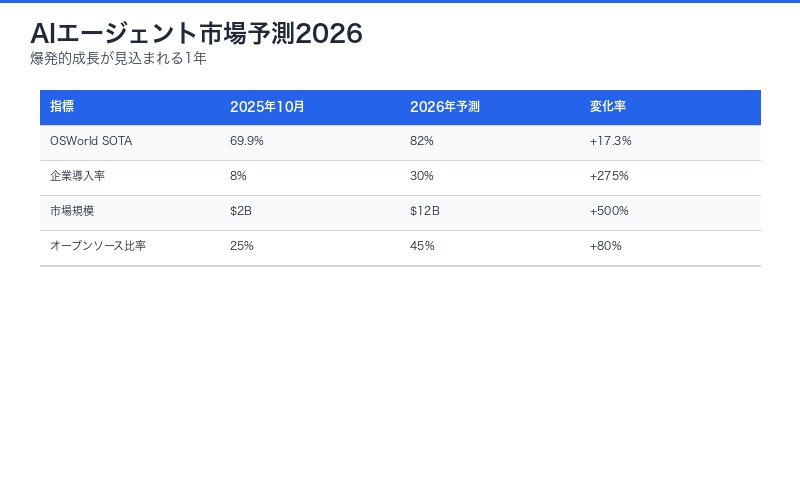
| 指標 | 2025年10月 | 2026年予測 | 変化率 |
|---|---|---|---|
| OSWorld SOTA | 69.9% | 82% | +17.3% |
| 企業導入率 | 8% | 30% | +275% |
| 市場規模 | $2B | $12B | +500% |
| オープンソース比率 | 25% | 45% | +80% |
読者への3つのアクションプラン
研究者・開発者の方へ:
- 📚 論文精読:arXiv:2510.02250を詳細に研究
- 💻 GitHub Clone:Agent Sリポジトリをローカル環境で試験
- 🧪 独自改善:bBoNアルゴリズムへの拡張を提案・実装
ビジネスリーダーの方へ:
- 📊 業務棚卸し:自動化可能な定型業務をリスト化
- 🎯 パイロット企画:小規模導入プロジェクトを立案
- 💰 ROI試算:投資対効果を具体的数値で評価
一般ビジネスパーソンの方へ:
- 🎓 スキル再定義:AIでは代替困難な能力を強化
- 🤝 協働学習:AIエージェントとの協働スキルを習得
- 🔮 キャリア戦略:自動化時代のキャリアパスを再設計
結論:
Agent S3は、AIエージェント技術が「研究室の実験」から「実世界の生産ツール」へと移行する歴史的転換点を象徴しています。
わずか1年で性能10倍という進化速度は、今後数年で**業務のあり方そのものを根本的に変革する**可能性を示唆しています。
この波に乗るか、取り残されるか。選択の時は、今です。
参考文献:
- Agent S3 Official Article: https://www.simular.ai/articles/agent-s3
- GitHub Repository: https://github.com/simular-ai/Agent-S
- Research Paper: arXiv:2510.02250
- OSWorld Benchmark: https://os-world.github.io/

関連記事:
【機械学習の物理学革命】ラグランジアンで統一される教師あり・生成・強化学習の最小作用原理
【AI懐疑論の三位一体】Bitter Lesson提唱者サットンまでスケーリング限界を認めた歴史的転換
【Factory CLI完全ガイド】カスタムドロイドで開発効率3倍:4ヶ月を3.5日にした移行事例
コメント