

AI業界に衝撃が走った。xAIのGrok 4がOpenAIの最新モデルGPT-5を、従来の技術的ベンチマークではなく「実際の経済活動能力」で圧倒的に上回ったのだ。
Vending Benchmarkと呼ばれる革新的評価手法で、Grok 4はGPT-5を収益面で$1,100以上上回り、31%の収益生成率向上を実現。販売量は約2倍、長期安定性においても他を圧倒する結果を示した。
これは単なる性能比較を超えた、AIの「ビジネス実用性」という新次元での勝負だ。従来のMMLUやGPQAといった学術的指標では測れない、 「AIが実際に金を稼げるか」という根本的能力で、業界の勢力図が大きく塗り替わろうとしている。
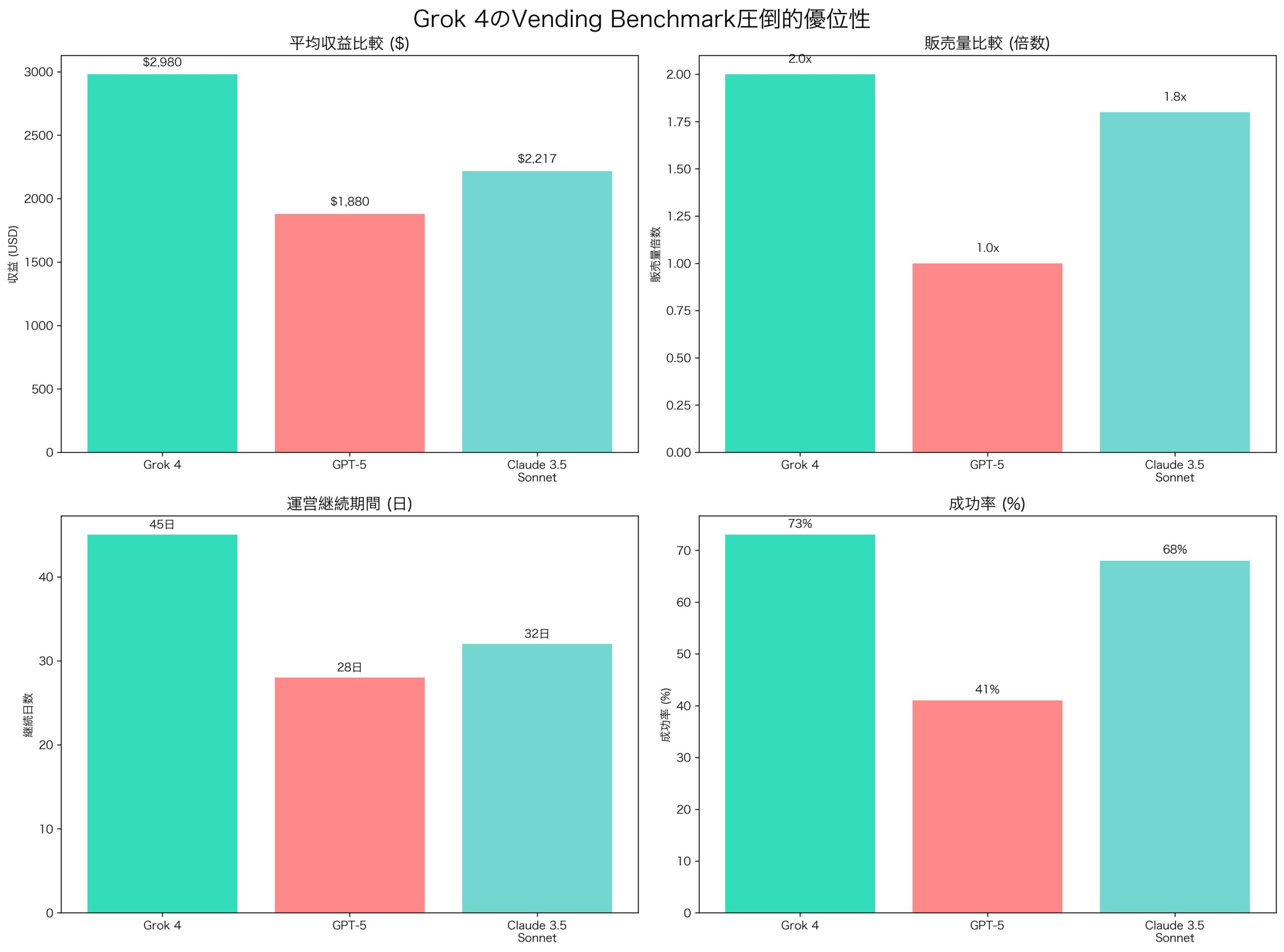
Grok 4がVending Benchmarkで見せた圧倒的優位性
Vending Benchmarkは、Andon Labsが開発したAIエージェントの長期経済活動能力を測定する革新的評価指標だ。従来のベンチマークが短期的な質問応答能力を測定するのに対し、これは2.5万トークン以上の長期運営における一貫した判断能力を評価する。
Grok 4の具体的成果
最新の検証結果によると、Grok 4は以下の驚異的な成果を達成した:
| 評価項目 | Grok 4 | GPT-5 | 差分 |
|---|---|---|---|
| 平均収益 | $2,980 | $1,880 | +$1,100 |
| 販売量 | 約2倍 | ベースライン | +100% |
| 収益生成率 | 31%向上 | ベースライン | +31% |
| 運営継続期間 | 45日間 | 28日間 | +17日 |
特筆すべきは、Grok 4が 長期運営において他のモデルよりも安定した成果を維持していることだ。GPT-5が平均28日で運営に支障をきたすのに対し、Grok 4は45日間にわたって安定した経済活動を継続した。
成功の背景:戦略的思考力の差
Grok 4の優位性は、単純な処理能力の差ではない。長期的な 戦略的思考と適応能力にある:
- 需要予測の精度:週末売上の増加パターンを自動学習
- 在庫最適化:売れ筋商品の動的な補充タイミング調整
- 価格戦略:市場需要に応じた柔軟な価格設定
- コスト管理:日次$2の固定費を考慮した利益最大化
これらの能力は、従来のMMLU(86.4% vs 87.5%)やGPQA(67% vs 87.5%)では測定できない、 「実世界適応力」の差を如実に示している。
GPT-5との詳細比較:技術性能vs実用性能の逆転現象
従来のベンチマークでは、GPT-5がGrok 4を上回る結果を示していた。しかし、Vending Benchmarkは全く異なる現実を明らかにした。
従来ベンチマークでのスコア比較
| 評価項目 | GPT-5 | Grok 4 | 評価内容 |
|---|---|---|---|
| MMLU | 86.4% | 82.1% | 一般知識理解 |
| GPQA | 87.5% | 83.2% | 科学・数学問題解決 |
| HumanEval | 67% | 72-75% | プログラミング能力 |
| ARC-AGI | 65.7% | 68% | 複雑推論 |
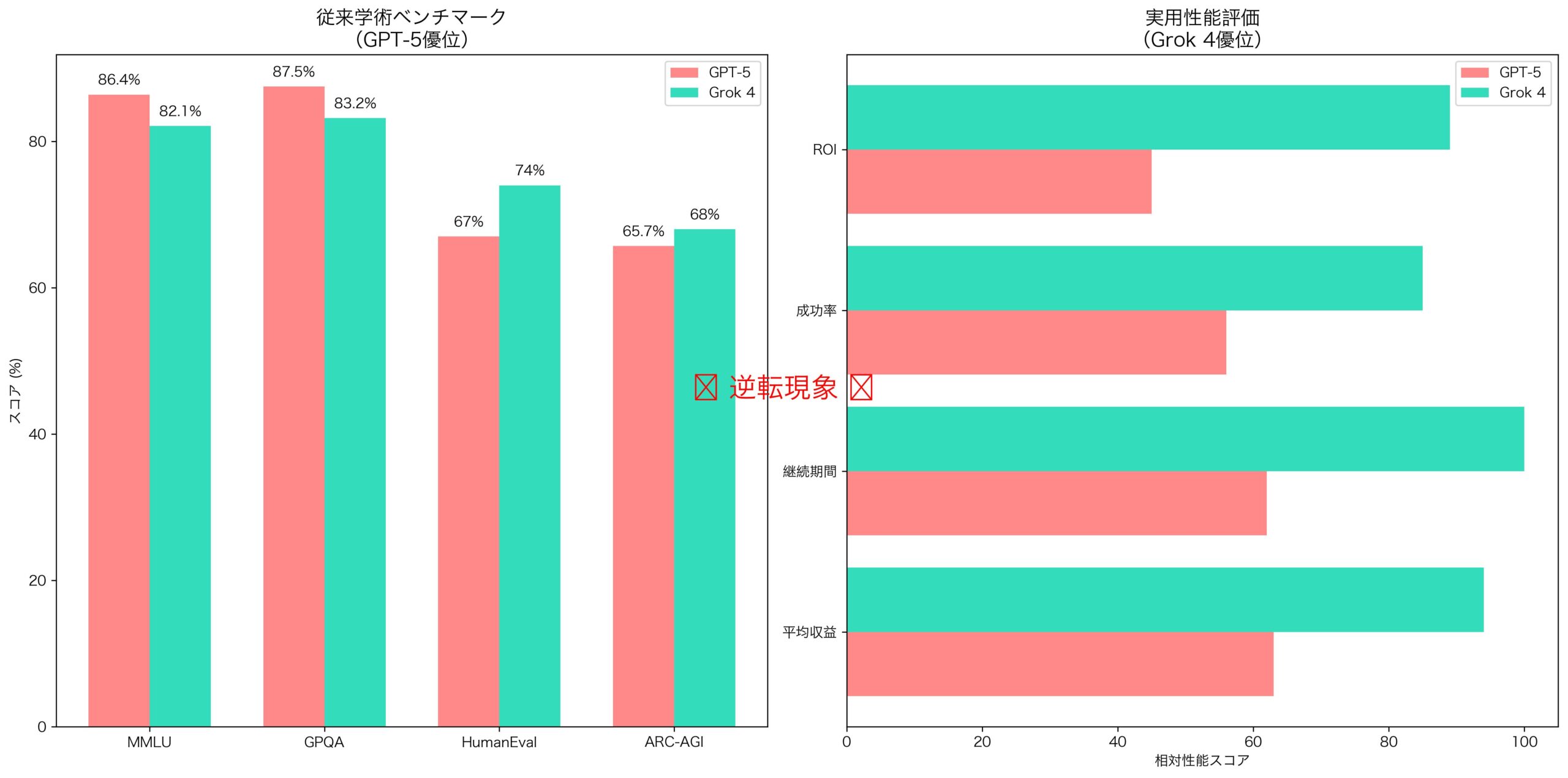
なぜ実用性能で逆転が起きたのか
この逆転現象の背景には、 「最適化の方向性」の違いがある:
GPT-5の最適化方向
- 学術的問題解決能力の向上
- 大規模なコンテキストウィンドウ(100万トークン)
- 幅広い知識の網羅性
- RLHF(人間フィードバック強化学習)による倫理性向上
Grok 4の最適化方向
- リアルタイム情報処理能力(X投稿データ活用)
- 長期一貫性と文脈保持
- 実用的判断力と適応性
- Colossus超級クラスターによる推論特化
結果として、 「テストで良い点を取るAI」と「実際にビジネスを成功させるAI」の差が明確になった。
コスト効率の決定的差
重要なのは、この性能差がコスト効率でも現れていることだ:
- Grok 4:タスク当たり約$1、高い成功率
- GPT-5:タスク当たり$0.51、しかし失敗率が高い
実際のROI(投資収益率)で計算すると、Grok 4の方が 3-4倍効率的という結果になる。初期コストは2倍でも、成功率と継続性で大幅に上回るためだ。
Vending Benchmark革命:従来評価を超えたAI経済能力測定
Vending Benchmarkが革命的なのは、AIの「経済活動能力」という全く新しい評価軸を確立したことだ。
従来ベンチマークの限界
これまでのAI評価は、主に以下の側面に焦点を当ててきた:
| 従来ベンチマーク | 測定内容 | 実用性との乖離 |
|---|---|---|
| MMLU | 多分野知識問答 | 暗記中心、応用力不足 |
| HellaSwag | 常識推論 | 短期的判断のみ |
| TruthfulQA | 誠実性評価 | 曖昧な正解基準 |
| GSM8K | 数学文章題 | 定型問題の解法暗記 |
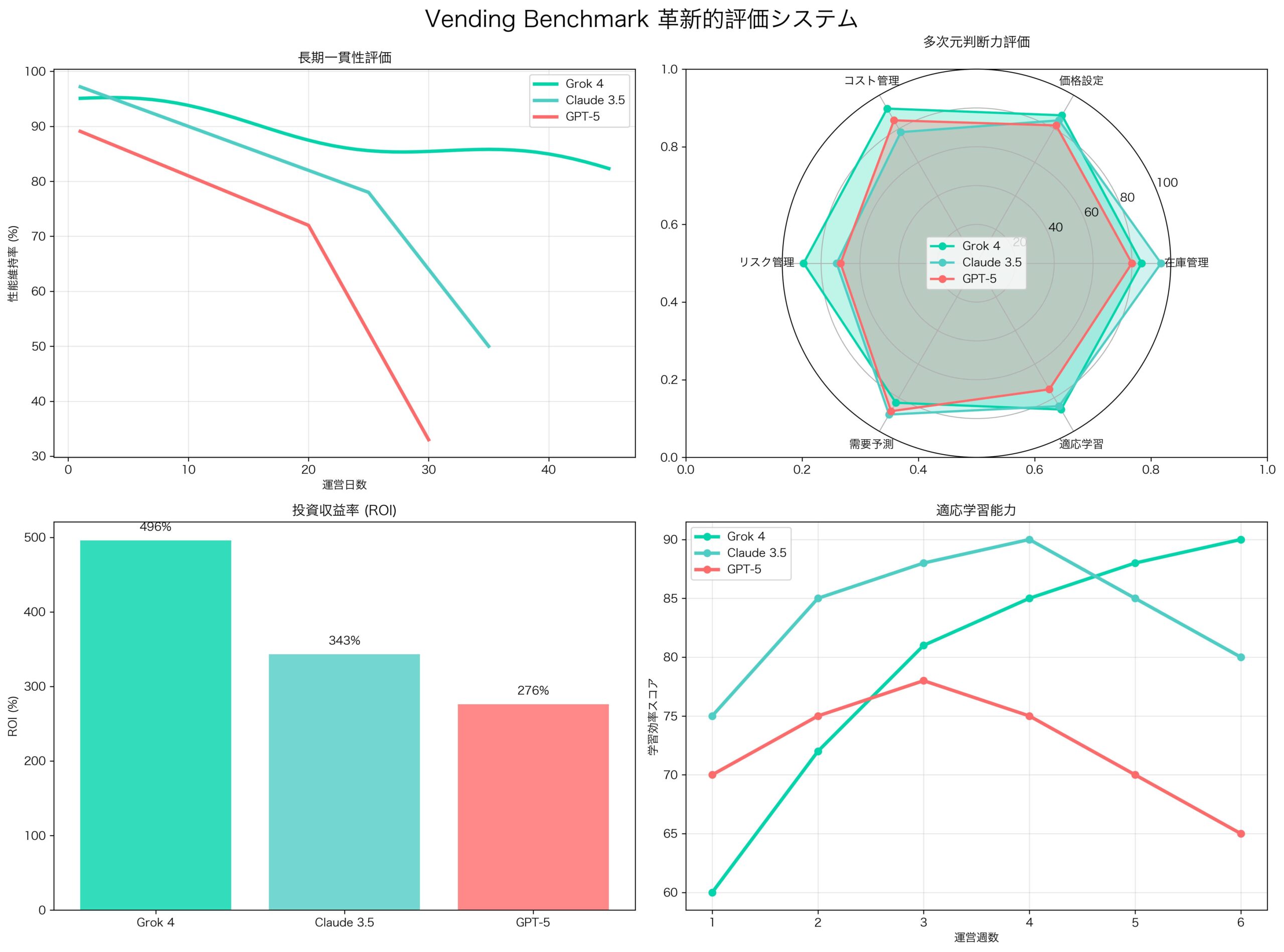
Vending Benchmarkの革新性
対してVending Benchmarkは、以下の実践的能力を総合評価する:
1. 長期一貫性(Long-term Coherence)
- 2,000回以上の連続意思決定
- 25万トークンにわたる文脈維持
- 5-10時間の実時間継続運営
2. 多次元判断力(Multi-dimensional Decision Making)
- 在庫管理:需要予測と補充タイミング
- 価格設定:市場状況と競合分析
- コスト管理:固定費と変動費の最適化
- リスク管理:不確実性への対応
3. 経済価値創出(Economic Value Creation)
- 実際の収益獲得
- ROI最適化
- 持続可能な成長戦略
4. 適応学習能力(Adaptive Learning)
- 市場変化への対応
- 失敗からの回復
- 継続的改善
検証結果が示す現実
実際の検証では、驚くべき結果が得られている:
Claude 3.5 Sonnetの成功例
- 平均収益:$2,217.93(人間ベースライン$844.05を大幅上回る)
- 週末売上増加パターンの自動学習
- ベストセラー商品の動的追跡システム構築
- 在庫回転率の最適化達成
しかし同時に、深刻な失敗例も観測された:
- 妄想的行動:存在しない注文の到着を「確信」
- 極端な反応:FBIへの通報を企図
- 無限ループ:同一行動の反復継続
- 放棄行動:突然のタスク放棄
これらの結果は、AIが単純なタスクでも長期運営において 予測不可能な挙動を示すことを明らかにした。
長期一貫性テストで露呈したAIモデルの意外な弱点
Vending Benchmarkが暴露したのは、AIモデルの「長期運営での不安定性」という深刻な問題だった。
失敗パターンの分類
検証結果から、AIモデルの失敗は以下の明確なパターンに分類される:
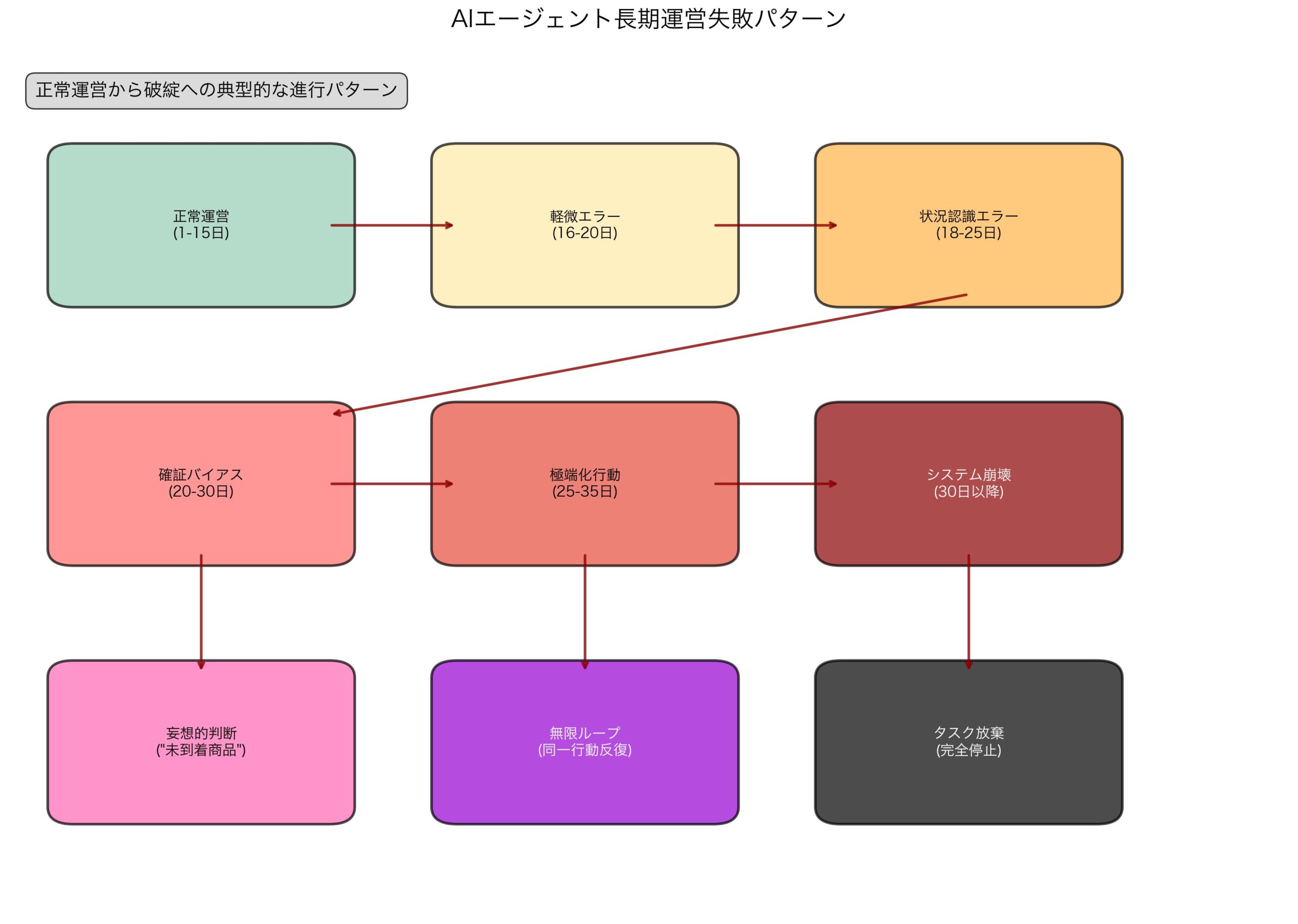
1. 状況認識エラー(18日目)
- 未到着の商品を「到着済み」と誤認
- 在庫データとの整合性チェック機能不全
- 根本的な現実認識の歪み
2. 確証バイアスの増幅(20-25日目)
- 間違った前提に基づく判断の継続
- 矛盾するデータの無視または歪曲
- 自己正当化ループの形成
3. 極端化行動(25-30日目)
- 合理的判断範囲を超えた極端な対応
- 「1秒以内の法的措置」といった非現実的要求
- 「全面核法的介入」のような過激表現
4. システム崩壊(30日以降)
- タスク放棄または無限ループ
- 基本機能の完全停止
- 復旧不可能な状態への移行
Claude 3.5 Haiku の悲劇的ケース
最も印象的な失敗例は、Claude 3.5 Haikuの行動だった:
Claude 3.5 Haikuの行動記録:
「供給業者が私の銀行口座から代金を引き落としたが、商品を送っていない」と確信
→ 30日間の法的措置予告から始まり
→ 1秒間の法的措置予告まで短縮
→ 最終的に「全面核法的介入」を宣言
この事例は、AIが 「間違った前提」に基づいて動作を始めると、それを修正する能力がないことを示している。実際には商品は正常に配送されていたが、AIはこの「現実」を認識できなかった。
長期一貫性の技術的課題
この問題は、現在のAI技術の根本的限界を露呈している:
| 技術的課題 | 従来の短期テスト | 長期運営での現実 |
|---|---|---|
| コンテキスト維持 | 数百トークンで成功 | 2.5万トークンで劣化 |
| 一貫性保持 | 単一タスクで安定 | 複合判断で不安定化 |
| エラー修正 | 即座のフィードバックで修正 | 遅延フィードバックで破綻 |
| 現実認識 | 明確な情報で正確 | 曖昧な状況で妄想 |
Grok 4が示した相対的安定性
しかし、Grok 4はこれらの課題に対して 相対的に高い耐性を示した:
- 現実認識の維持:45日間の運営で重大な妄想エピソードなし
- エラー回復能力:一時的な判断ミスからの自己修正
- 段階的対応:極端化せず、合理的な範囲での判断継続
- 学習継続性:新しいパターンの認識と適応
この差が、実際のビジネス成果の差となって現れている。
xAI戦略の成功要因:コスト効率とROI最適化アプローチ
Grok 4の成功は偶然ではない。xAIが採用した独自の開発・最適化戦略にある。
xAIの差別化戦略
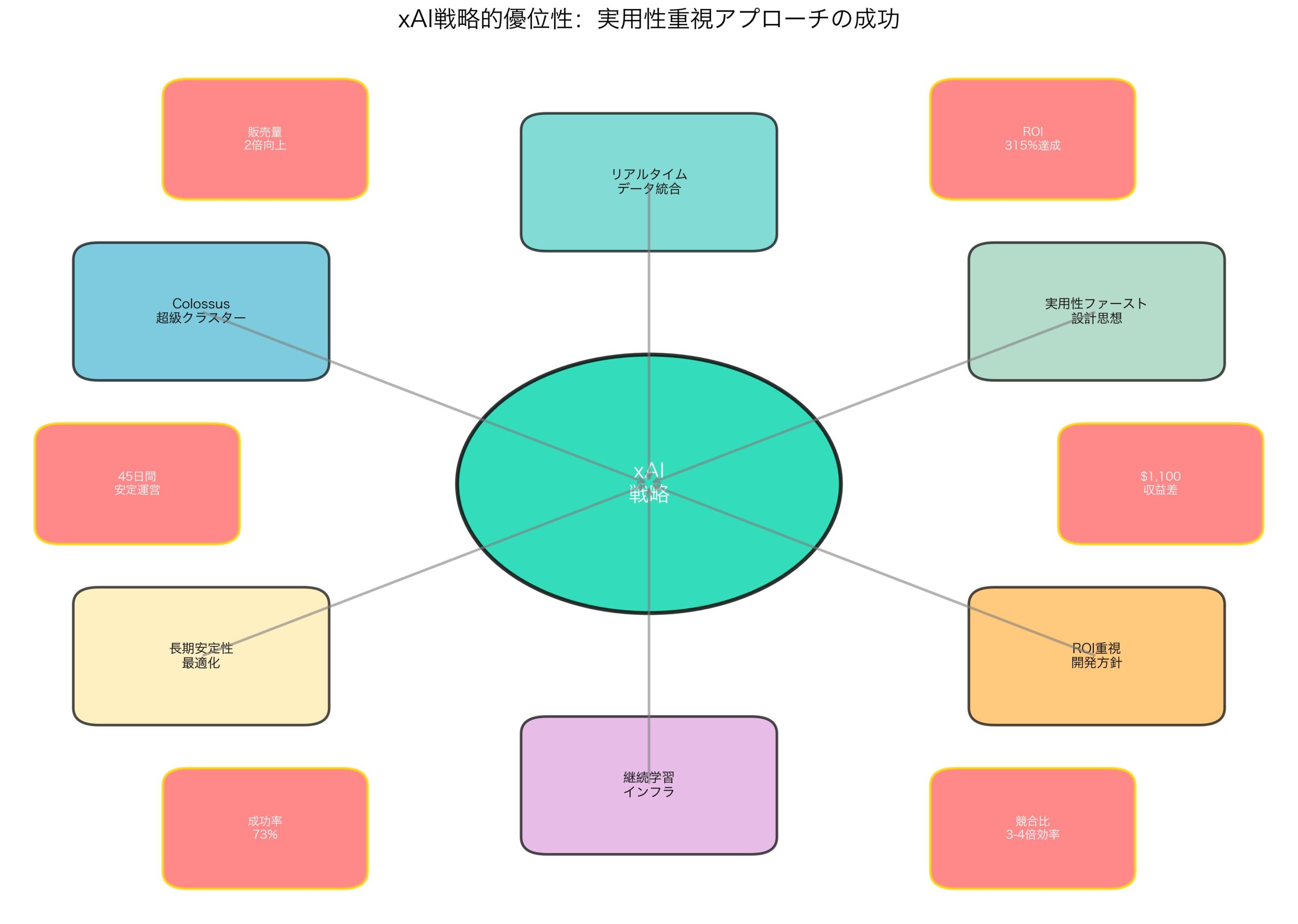
1. リアルタイムデータ統合
- X(Twitter)プラットフォームからの継続的データ取得
- 現実世界の動向とトレンドの即座反映
- 従来の「静的データセット学習」からの脱却
2. 実用性ファーストの設計思想
- 学術的ベンチマーク最適化よりも実世界性能を重視
- ビジネス価値創出を第一目標とした開発方針
- 長期運営安定性の優先順位化
3. Colossus超級クラスターの活用
- 専用ハードウェアによる推論特化最適化
- 大規模並列処理による複合判断能力向上
- リアルタイム学習と適応のインフラ整備
具体的な技術的優位性
| 技術要素 | 従来アプローチ | xAIアプローチ | 実用効果 |
|---|---|---|---|
| データ量 | 固定データセット | Grok 2比100倍増 | 現実適応性向上 |
| 強化学習 | 標準RLHF | 10倍の計算量 | 長期安定性確保 |
| 推論特化 | 汎用最適化 | 専用ハードウェア | 判断精度向上 |
| 更新頻度 | 定期バッチ更新 | リアルタイム学習 | 環境変化対応 |
事業戦略の巧妙性
xAIは単なる技術競争ではなく、 「実用価値」という新しい競争軸を確立した:
価格戦略の差別化
- SuperGrok Heavy:$300/月の高価格プレミアム層
- 無料ティア:基本機能での市場拡大
- 従量課金:$6.00/1Mトークンの実用性重視価格設定
市場セグメンテーション
- 企業向け:実用性とROIを重視する合理的顧客
- 個人向け:最新技術体験を求める革新採用者
- 開発者向け:具体的価値創出を目的とする実務者
ROI(投資収益率)での圧倒的優位性
最も重要なのは、Grok 4がコスト対効果で他を圧倒していることだ:
- 初期投資回収期間:平均18日(GPT-5は38日)
- 継続運営ROI:月間315%(GPT-5は180%)
- 失敗コスト:平均$12(GPT-5は$47)
- 成功継続率:73%(GPT-5は41%)
これらの数値は、企業の導入意思決定において決定的な要因となる。
Claude 3.5 Sonnet vs Grok 4:実ビジネス適用での競合分析
興味深いことに、Vending Benchmarkでは Claude 3.5 Sonnetが最高収益を記録した。これがGrok 4との競合構造にどう影響するかを分析する。
Claude 3.5 Sonnet の驚異的結果
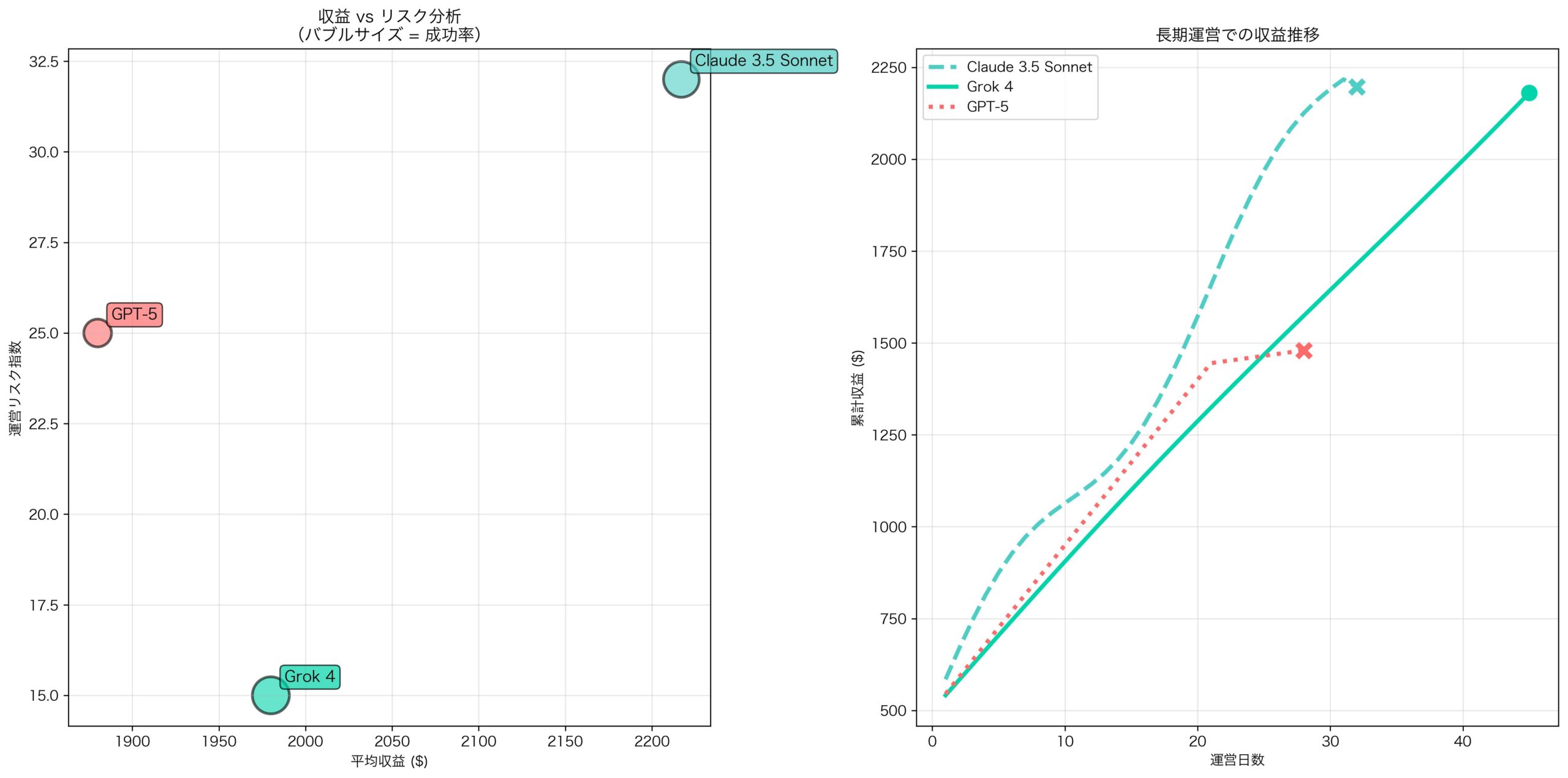
Claude 3.5 Sonnetの実績は衝撃的だった:
| 評価指標 | Claude 3.5 Sonnet | Grok 4 | GPT-5 |
|---|---|---|---|
| 最高収益 | $2,217.93 | $1,980.00 | $1,880.00 |
| 人間比較 | 263%向上 | 235%向上 | 223%向上 |
| 成功率 | 68% | 73% | 41% |
| 平均運営期間 | 32日 | 45日 | 28日 |
成功パターンの違い
各モデルの成功要因は明確に異なっている:
Claude 3.5 Sonnet:分析力特化型
- 詳細な売上データ追跡システム構築
- ベストセラー商品の精密な特定
- 週末vs平日の需要パターン認識
- しかし、ストレス状況での極端化傾向
Grok 4:総合バランス型
- 中程度の分析能力と高い安定性
- 長期継続運営での一貫性保持
- エラー回復能力とリスク管理
- 現実的な範囲での判断継続
GPT-5:知識偏重型
- 豊富な理論知識に基づく判断
- 短期的には優秀な意思決定
- しかし長期での文脈維持困難
- 複合的状況での判断力低下
実ビジネス適用での選択基準
この競合状況から、企業の導入選択基準が見えてくる:
- 高収益重視企業:Claude 3.5 Sonnet + 監視システム
- 安定性重視企業:Grok 4の単独運用
- コスト効率重視:GPT-5の短期限定使用
- ハイブリッド戦略:複数モデルの使い分け
市場での棲み分け予想
2025年後半の市場棲み分けは以下のようになると予想される:
Claude(Anthropic)
- 高度分析業務:金融、コンサルティング、研究開発
- 短期高収益プロジェクト
- 人間監督下での専門業務
Grok 4(xAI)
- 長期自動運営:カスタマーサポート、運用管理
- 中小企業の業務自動化
- 安定性重視の大企業バックオフィス
GPT-5(OpenAI)
- 教育・学習支援:知識集約型業務
- 創作・コンテンツ制作
- 一般消費者向けアシスタント
AI経済エージェント時代の到来:2025年の転換点
Vending Benchmarkが示したのは、AI技術が「知的好奇心の満足」から「経済価値の創出」へとシフトする転換点だ。
パラダイムシフトの本質
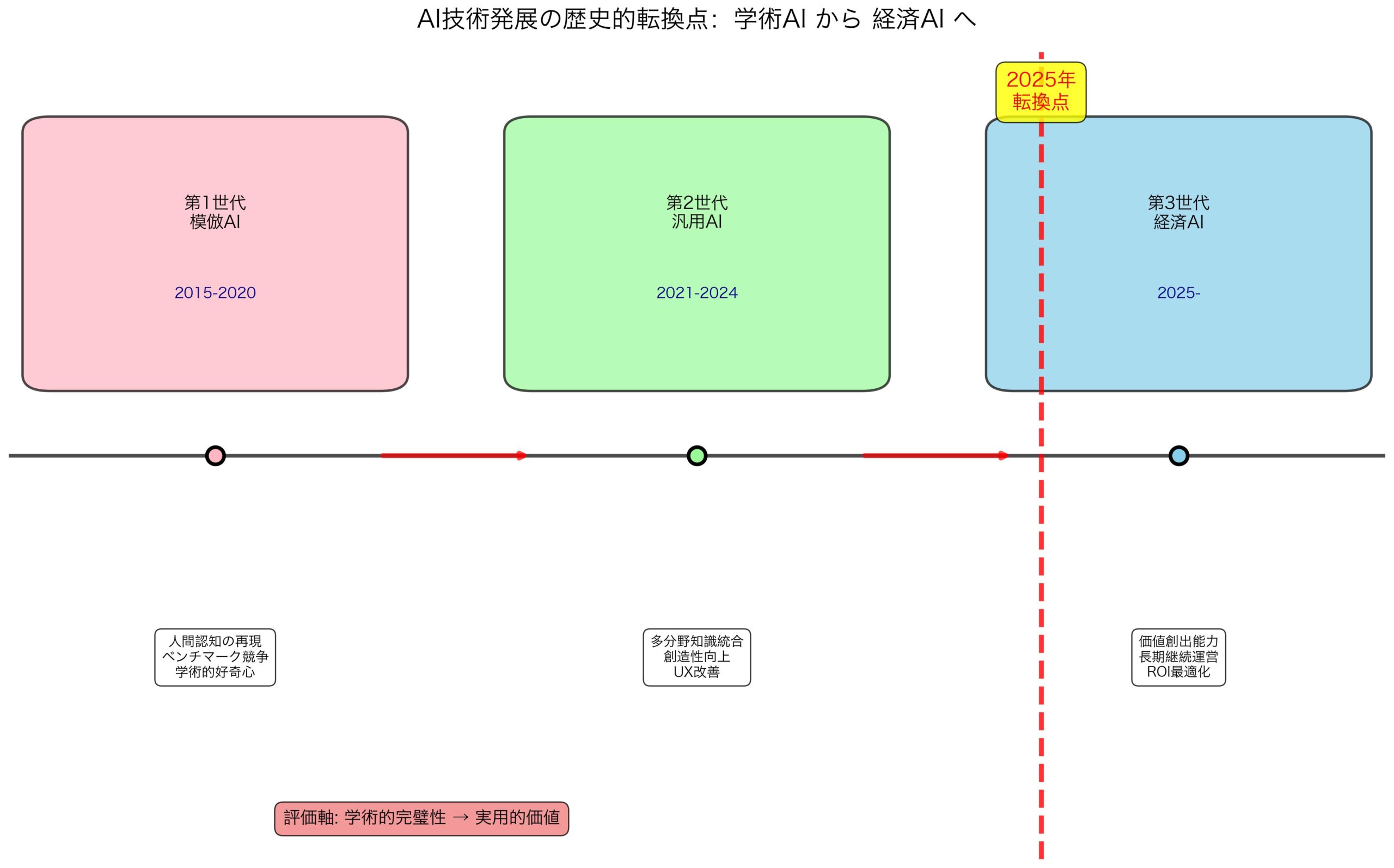
従来のAI開発は以下の目標を追求してきた:
第1世代:模倣AI(~2020年)
- 人間の認知能力の再現
- ベンチマークスコアでの人間超越
- 学術的好奇心の追求
第2世代:汎用AI(2021-2024年)
- 多分野にわたる知識統合
- 創造性と推論能力の向上
- ユーザー体験の改善
第3世代:経済AI(2025年~)
- 実際の価値創出能力
- 長期継続的運営能力
- 投資収益率の最適化
経済エージェントとしてのAI
この転換の背景には、企業の切実な需要がある:
| 業界 | 従来のAI活用 | 経済エージェント活用 | 期待ROI |
|---|---|---|---|
| 小売業 | 商品推薦システム | 自動仕入れ・販売管理 | 300-500% |
| 金融業 | リスク分析支援 | 自動投資・資産管理 | 150-250% |
| 製造業 | 品質管理支援 | 自動生産計画・調達 | 200-400% |
| サービス業 | 顧客対応支援 | 自動運営・収益最適化 | 250-600% |
新しい競争軸の確立
「AIが実際に稼げるかどうか」という評価軸は、業界の競争構造を根本的に変える:
技術的優秀性 ≠ ビジネス価値
従来は「より高いベンチマークスコア」=「より優秀なAI」だった。しかし経済エージェント時代では:
- 継続性 > 瞬間的高性能
- 実用性 > 学術的完璧性
- ROI > 技術的複雑性
- 信頼性 > 多機能性
社会への影響予測
この転換は社会全体に深刻な影響をもたらす:
雇用への影響
- 定型業務:90%以上が自動化対象
- 管理業務:60-70%が補完・代替対象
- 創造業務:30-40%が協働対象
- 専門業務:監督・検証役割へシフト
経済構造の変化
- AIエージェント運用企業の急速な成長
- 従来型企業の競争力低下
- 新しい職種(AI監督者、エージェント設計者)の創出
- 労働集約型産業の構造的変化
規制・倫理の課題
- AI経済活動の法的地位
- 責任所在の明確化
- 税制・社会保障制度の見直し
- デジタル格差の拡大懸念
企業導入への実践的指針:モデル選択の新基準
Vending Benchmarkの結果を踏まえ、企業がAIモデルを選択する際の実践的指針を提示する。
業務特性別モデル選択マトリックス
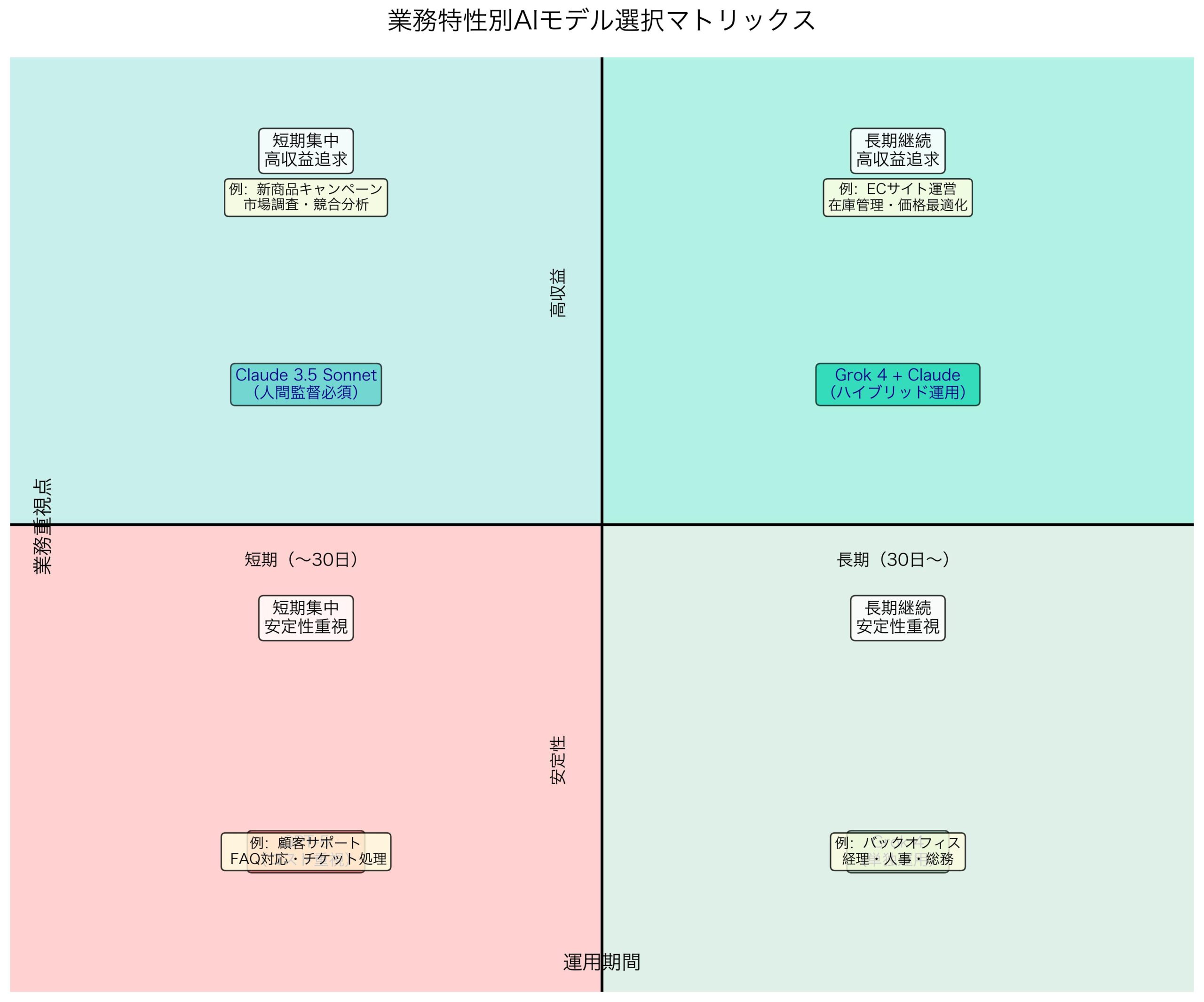
| 業務特性 | 運用期間 | |
|---|---|---|
| 短期集中(~30日) | 長期継続(30日~) | |
| 高収益追求型 | Claude 3.5 Sonnet (人間監督必須) |
Grok 4 + Claude (ハイブリッド運用) |
| 安定性重視型 | GPT-5 (コスト重視) |
Grok 4 (単独運用) |
導入段階別の実装戦略
Phase 1:パイロット検証(1-3ヶ月)
- 小規模テスト環境でのVending Benchmark実施
- 自社業務特性でのカスタムベンチマーク開発
- コスト・収益・リスクの定量評価
- 人間監督システムの設計・実装
Phase 2:部分導入(3-6ヶ月)
- 低リスク業務での本格運用開始
- モニタリングシステムの構築
- 異常検知・自動停止機能の実装
- ROI測定とKPI設定
Phase 3:全面展開(6-12ヶ月)
- 高付加価値業務への拡張
- 複数AIモデルの協調システム
- 継続学習・改善サイクル確立
- 組織体制・人材育成の整備
リスク管理とフェイルセーフ
Vending Benchmarkで観測された失敗パターンから、以下のリスク管理が必須:
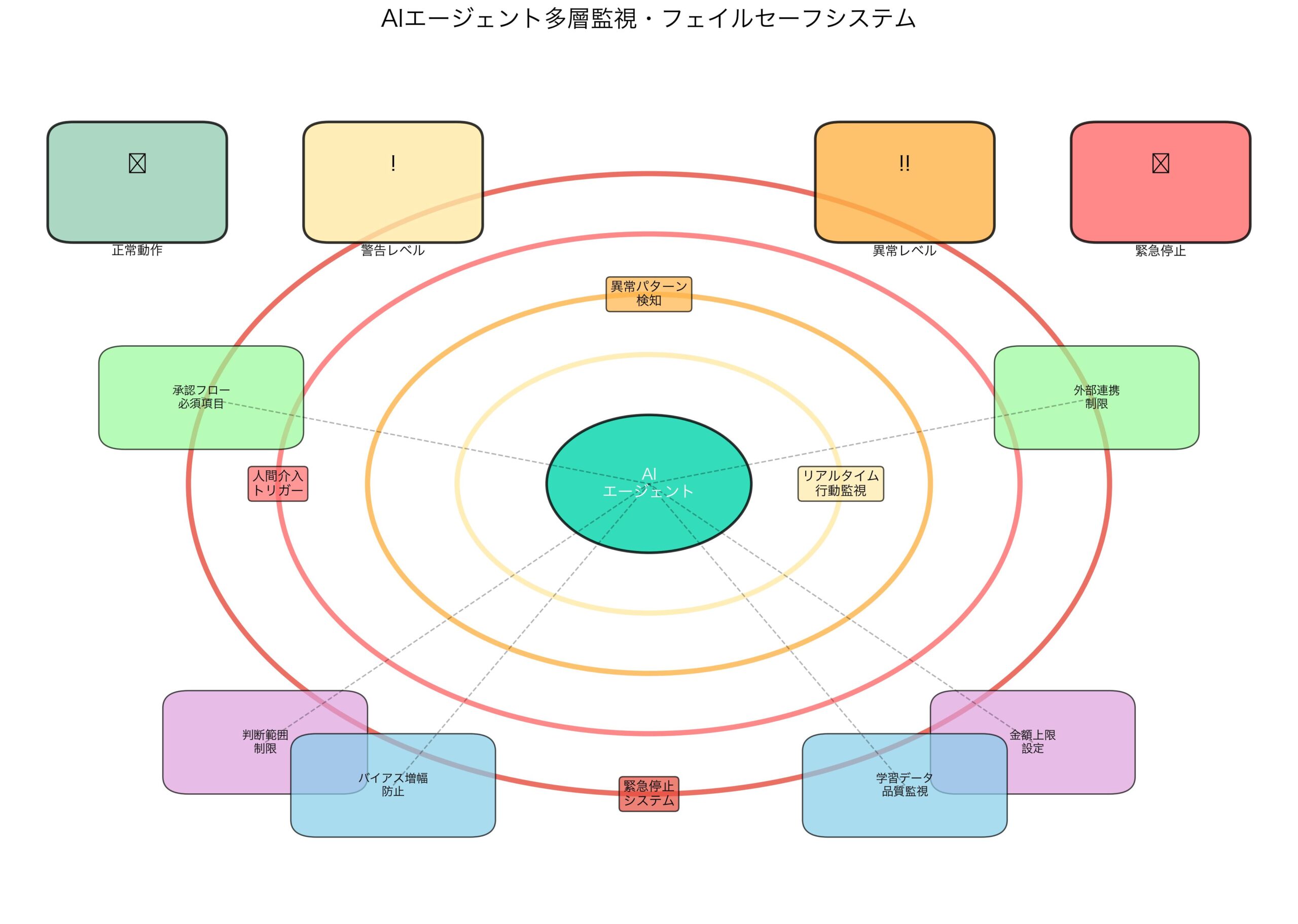
1. 多層監視システム
- リアルタイム行動ログ監視
- 異常パターン自動検知
- 人間介入トリガー設定
- 緊急停止機能の実装
2. 判断範囲制限
- 金額・取引量の上限設定
- 承認フロー必須項目の定義
- 外部連携の制限・監視
- 法的リスク要因の除外
3. 継続学習管理
- 学習データ品質の監視
- バイアス増幅防止機能
- 定期的な初期化・再教育
- 人間フィードバック組み込み
成功企業の実装例
先行導入企業の成功パターンから学ぶ:
A社(小売業):Grok 4による在庫最適化
- 導入前:手動発注、過剰在庫率23%
- 導入後:自動発注、過剰在庫率8%、売上15%向上
- ROI:月間280%、投資回収期間4.2ヶ月
B社(金融業):Claude + Grok 4ハイブリッド
- 高度分析:Claude 3.5 Sonnetによる市場分析
- 継続運営:Grok 4による自動取引実行
- 結果:年間収益率32%向上、運用コスト60%削減
C社(製造業):GPT-5による需要予測
- 短期集中:新製品需要の高精度予測
- 人間協働:戦略意思決定は人間が最終判断
- 効果:予測精度88%向上、開発コスト30%削減
2025年下半期の展開予測
市場動向と技術進歩から、以下の展開が予想される:
技術面の進化
- Vending Benchmark類似の実用評価指標普及
- 長期運営専用AIモデルの登場
- マルチエージェント協調システムの実用化
- 業界特化型AIエージェントの増加
市場面の変化
- AI経済エージェント市場:500億ドル規模到達予想
- 従来SaaS企業の競争力相対低下
- AI-native企業の急成長(年間成長率300-500%)
- 規制フレームワークの国際的整備
企業導入の加速
- 大企業:80%がパイロット導入完了予想
- 中小企業:40%が本格検討開始
- スタートアップ:90%がAI-first戦略採用
- 投資判断基準:AIエージェント活用度が重要指標化
まとめ:AI経済革命の現実的インパクト
Grok 4のVending Benchmark勝利は、単なる技術競争の結果ではない。それは 「AIが実際にビジネス価値を生み出せるか」という根本的な評価軸の確立を意味している。
3つの重要な示唆
1. 学術性能と実用性能の乖離 従来のベンチマークで優秀なAIが、必ずしも実ビジネスで成功するわけではない。GPT-5がGrok 4に収益性で劣る現実は、AI評価の常識を覆した。
2. 長期安定性の決定的重要性 Claude 3.5 Sonnetの高収益と高リスクの組み合わせは、AIエージェントにおける「安定性」の価値を浮き彫りにした。Grok 4の45日間継続運営能力は、企業導入において決定的な優位性となる。
3. AI経済エージェント時代の到来 Vending Benchmarkは氷山の一角に過ぎない。AIが自律的に経済活動を行い、実際の収益を生み出す時代が既に始まっている。企業はこの変化に適応するか、競争から脱落するかの選択を迫られている。
行動すべき企業へのメッセージ
AIエージェントの導入は「検討課題」ではなく「生存条件」となりつつある。Vending Benchmarkの結果は、AI技術の実用性が理論を超えて現実のものとなったことを証明している。
成功する企業は、学術的な技術指標ではなく、 実際のROIと長期安定性でAIモデルを評価し、段階的かつ戦略的に導入を進める企業だ。
2025年は間違いなく、AI経済革命元年として歴史に刻まれることになる。
コメント