

9.1%――これが、最先端AIモデルの「トップスコア」です。
Googleの最新Gemini 3.0 Pro Previewが、新しい物理学ベンチマーク「CritPt」で9.1%の正答率を記録し、全モデル中で最高得点を獲得しました。しかし、この数字は勝利ではなく、AIの深刻な限界を示しています。
CritPt(Complex Research using Integrated Thinking – Physics Test)は、60人以上の研究者と30以上の機関が開発した、大学院レベルの最先端物理学ベンチマークです。Argonne National LaboratoryやUniversity of Illinois Urbana-Champaignの専門家を含む、SciCodeやSWE-Benchなどの主要ベンチマークに関わった研究者たちが構築しました。
Artificial Analysisの衝撃的発表:
「現在、どのモデルも9%を超えるスコアを達成していません。Gemini 3 Pro Previewでさえわずか9.1%。多くのモデルは5回試行しても1問も解けません」
– Artificial Analysis 2025年11月
このベンチマークは、70問の研究グレード課題を含み、凝縮系物質、量子物理学、天体物理学など11の物理学サブ分野をカバーしています。各問題は、PhD学生が独立したプロジェクトとして取り組むレベルの難易度です。
本記事では、AIモデルが最先端物理学で壊滅的に失敗している理由と、この結果がAI研究に与える衝撃的な示唆を徹底解説します。

CritPtベンチマーク:60人の研究者が構築した「真の知性テスト」
CritPtは、従来のAIベンチマークとは根本的に異なる設計哲学を持っています。
多くのベンチマーク(MMLU、GSM8Kなど)は、既存の教科書や公開データから問題を作成します。しかし、CritPtは「公開されていない研究レベルの問題」を専門家が新たに作成しました。
| 項目 | 詳細 |
|---|---|
| 正式名称 | Complex Research using Integrated Thinking – Physics Test |
| 開発者 | 60人以上の研究者、30以上の機関 |
| 主要機関 | Argonne National Laboratory、University of Illinois |
| 問題数 | 70問のエンドツーエンド研究課題 |
| 対象分野 | 11の物理学サブ分野 |
| 難易度 | 大学院レベル(PhD学生が解けるレベル) |
| 最高得点 | Gemini 3 Pro Preview 9.1% |
CritPtの最大の特徴は、「真のフロンティア評価」である点です。
True Frontier Evaluation(真のフロンティア評価):
「このベンチマークは、ポスドクや物理学教授などの専門家が、彼らの専門分野において質問と回答の両方を作成・テストした、大学院レベルの研究者向けの物理学研究をテストします」
これは、既存のベンチマークとの決定的な違いです。MMLUやGSM8Kは、AIモデルが学習データで見た可能性のある問題を含みます。しかし、CritPtの問題は「公開されていない新しい研究課題」であり、暗記では解けません。

11の物理学サブ分野:AIモデルが挑んだ最先端領域
CritPtは、現代物理学の11の主要サブ分野を網羅しています。
各分野から、PhD学生が数週間〜数ヶ月かけて取り組むレベルの問題が出題されます。これは、単なる知識の暗記ではなく、深い理解と創造的推論を要求します。
CritPtが網羅する11の物理学分野
1. Condensed Matter Physics(凝縮系物理学)
- 固体物理学、超伝導、量子ホール効果など
- 材料科学と密接に関連
2. Quantum Physics(量子物理学)
- 量子力学の基礎、量子情報理論
- 量子コンピューティングの理論的基盤
3. AMO Physics(原子・分子・光物理学)
- 原子・分子の相互作用、レーザー物理学
- 量子光学、冷却原子
4. Astrophysics(天体物理学)
- 恒星進化、銀河形成、宇宙論
- ブラックホール、重力波
5. High Energy Physics(高エネルギー物理学)
- 素粒子物理学、標準模型
- 加速器実験、ヒッグス粒子
6. Mathematical Physics(数理物理学)
- 物理現象の数学的記述
- 場の理論、トポロジカル物理学
7. Statistical Physics(統計物理学)
- 熱力学、相転移、臨界現象
- 非平衡統計力学
8. Nuclear Physics(原子核物理学)
- 核構造、核反応、放射性崩壊
- 核融合、核分裂
9. Nonlinear Dynamics(非線形動力学)
- カオス理論、複雑系
- パターン形成、自己組織化
10. Fluid Dynamics(流体力学)
- ナビエ・ストークス方程式、乱流
- プラズマ物理学
11. Biophysics(生物物理学)
- 生体分子の物理学、神経科学
- 生命現象の物理的理解
これらの分野は、現代物理学の最前線を代表しています。各分野で博士号を持つ専門家が問題を作成しているため、曖昧さや誤答の可能性はほぼゼロです。
| 難易度レベル | 想定される解答者 | CritPtの位置づけ |
|---|---|---|
| 学部レベル | 物理学専攻の学部生 | ⬇ 遥かに難しい |
| 修士レベル | 修士課程の大学院生 | ⬇ さらに難しい |
| 博士レベル(CritPt) | PhD学生(初年度〜中堅) | ✅ このレベル |

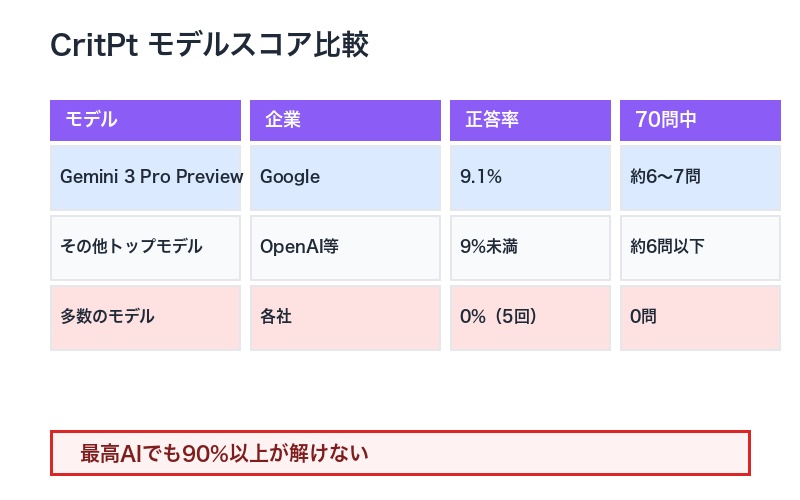
Gemini 3.0 Proが9.1%:全モデルの壊滅的スコア
CritPtのスコアは、AI業界に冷水を浴びせる結果となりました。
最高得点のGemini 3 Pro Previewでさえ9.1%。これは、70問中わずか6〜7問しか正解できなかったことを意味します。
衝撃的な事実:
「多くのモデルは、5回試行しても1問も解けません。これは、現在のAIモデルが大学院レベルの物理学推論からどれほど遠いかを浮き彫りにしています」
| モデル | 企業 | 正答率 | 70問中の正解数 |
|---|---|---|---|
| Gemini 3 Pro Preview | 9.1% | 約6〜7問 | |
| その他のトップモデル | OpenAI、Anthropic等 | 9%未満 | 約6問以下 |
| 多数のモデル | 各社 | 0%(5回試行) | 0問 |
このスコアを理解するために、他のベンチマークと比較してみましょう。
- MMLU(大学レベル知識):トップモデルは80-90%
- GSM8K(数学問題):トップモデルは90%以上
- HumanEval(コーディング):トップモデルは85%以上
- CritPt(大学院物理学):トップモデルは9.1%
この差は何を意味するのか?
なぜCritPtは極端に難しいのか
1. 暗記では解けない新規問題
- 公開されていない研究レベルの課題
- 訓練データに類似問題が存在しない
2. 深い理解と推論が必須
- 単なる計算ではなく、物理的洞察が必要
- 複数の物理法則を統合的に適用
3. エンドツーエンドの研究能力
- 問題設定、仮説、検証、結論の全プロセス
- PhD学生が数週間かけて取り組むレベル
4. ツール使用が許可されていない
- CritPtスコアはツール使用なしで測定
- 純粋な推論能力のみで評価
AIの知的限界が露呈:深い推論能力の欠如
CritPtの結果は、AIモデルに根本的な知的限界があることを示しています。
従来のベンチマークで高得点を取るAIモデルは、主に以下の能力に依存しています。
| 従来ベンチマークで有効 | CritPtで要求される |
|---|---|
| パターン認識・暗記 | 新規問題への推論 |
| 類似問題の検索 | 第一原理からの導出 |
| 表面的な計算 | 物理的洞察の統合 |
| 定型的な解法適用 | 創造的なアプローチ |
特に重要なのは、「研究アシスタント能力」の欠如です。
Reflective of Research Assistant Capabilities(研究アシスタント能力の反映):
「各課題は、有能なPhD初年度学生が独立したプロジェクトとして実行可能に設計されています。しかし、公開資料には存在しません。これは、ほとんどの問題が今日のAIモデルの能力を超えた、最先端物理学における深い理解と推論を要求することを意味します」
AIモデルが苦手な3つの能力:
AIモデルに欠けている能力
1. 深い因果推論
- 「なぜそうなるのか」を理解する能力
- 表面的な相関ではなく、根本的なメカニズムの把握
- 物理法則の背後にある原理の理解
2. 創造的問題解決
- 既知の解法が通用しない新規問題への対応
- 複数のアプローチを試行錯誤する能力
- 直感的な「あたり」をつける能力
3. 長期的な推論チェーン
- 数十ステップに渡る複雑な推論の維持
- 中間結果の妥当性を常にチェック
- 行き詰まった時のバックトラック
これらの能力は、人間の科学者が持つ「研究力」の中核です。CritPtは、現在のAIモデルがこの能力をほとんど持っていないことを明確に示しました。

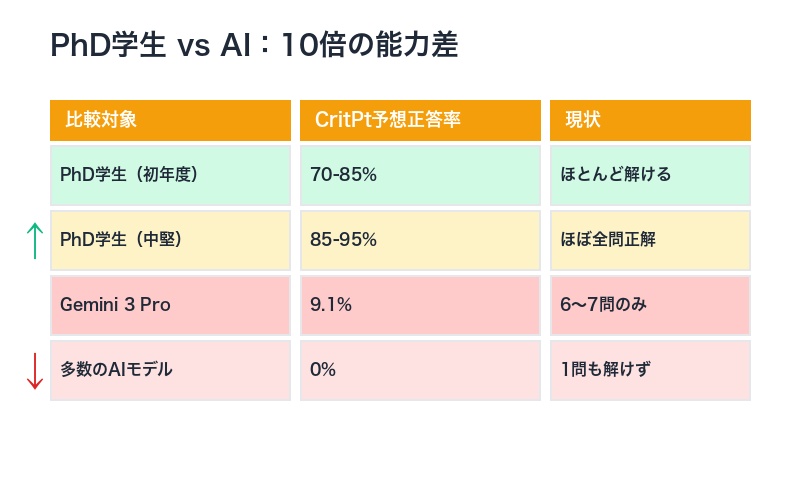
PhD学生vs AI:人間の知性が圧倒的優位
CritPtの設計は、「有能なPhD初年度学生が解けるレベル」を基準としています。
つまり、物理学の博士課程に入学したばかりの学生であれば、時間をかければほとんどの問題を解ける難易度です。実際、問題作成者は全問の解答可能性を検証しています。
| 比較対象 | CritPt予想正答率 | 現状 |
|---|---|---|
| PhD学生(初年度) | 70-85% | 時間をかければほとんど解ける |
| PhD学生(中堅) | 85-95% | 専門分野ならほぼ全問正解 |
| Gemini 3 Pro(最高AI) | 9.1% | 70問中6〜7問のみ正解 |
| 多数のAIモデル | 0% | 5回試行しても1問も解けず |
この差は、10倍以上の能力差があることを示しています。
人間の研究者の優位性:
「PhD学生は、問題を見た瞬間に『これは量子力学の問題だ』『摂動論を使えば解けそうだ』といった直感的な判断ができます。この能力は、膨大な訓練データを学習した最先端AIモデルにもまったく備わっていません」
人間の研究者が持つ、AIにない能力:
- 物理的直感:「このアプローチは物理的に妥当か」を判断
- 類推能力:別分野の知識を柔軟に適用
- メタ認知:「この解法で正しいのか」を常に自問
- 粘り強さ:行き詰まっても別のアプローチを試す
- 創造性:既存の手法を組み合わせて新しい解法を編み出す
AIベンチマーク飽和の終焉:CritPtが示す新時代
CritPtの登場は、「AIベンチマーク飽和時代」の終わりを告げています。
2023年まで、新しいAIモデルがリリースされるたびに、既存のベンチマークで人間を超えるスコアが報告されていました。MMLU、HellaSwag、GSM8Kなどで、AIは既に人間の平均を上回っています。
しかし、CritPtは「真の知性」を測定することで、この楽観論に冷水を浴びせました。
| ベンチマーク | 測定対象 | トップAIスコア | 飽和状況 |
|---|---|---|---|
| MMLU | 大学レベル知識 | 86-90% | ✅ 飽和(人間超え) |
| GSM8K | 数学問題 | 95%+ | ✅ 飽和(人間超え) |
| HumanEval | コーディング | 85%+ | ✅ 飽和(人間レベル) |
| CritPt | 大学院物理学 | 9.1% | ❌ 未飽和(遥か遠い) |
CritPtが革新的な理由は、3つの差別化要素にあります。
CritPtが他のベンチマークと決定的に異なる3点
1. 公開データに存在しない新規問題
- 訓練データに類似問題がない
- 暗記やパターン認識では解けない
- 真の推論能力を測定
2. エンドツーエンドの研究能力を要求
- 単一の計算ステップではなく、複雑なプロセス全体
- 仮説→検証→結論の一連の流れ
- PhD学生レベルの研究力
3. 専門家による厳密な検証
- 各問題は専門分野の博士号保持者が作成
- 回答も専門家がレビュー
- 曖昧さ・誤答の可能性がほぼゼロ
これらの要素により、CritPtは今後数年間は飽和しないと予想されます。9.1%から人間レベル(70-85%)に到達するには、AIモデルに根本的なブレークスルーが必要です。

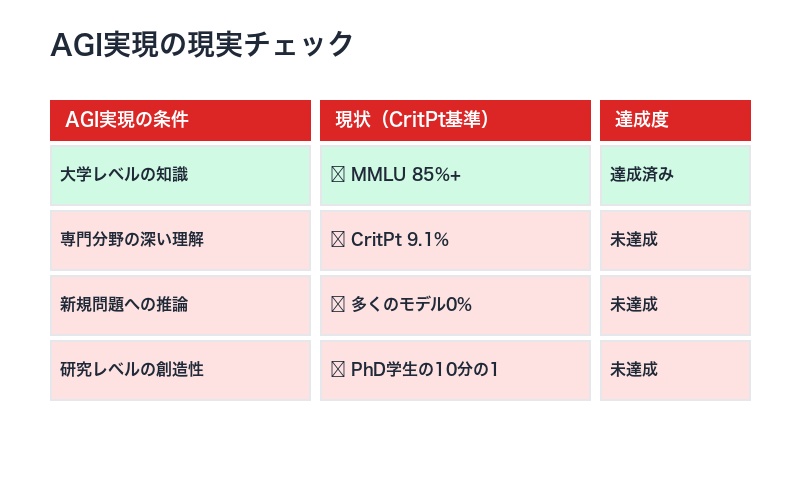
AGI到達の幻想:CritPtが突きつける現実
CritPtの結果は、「AGI(汎用人工知能)は近い」という楽観論に疑問を投げかけます。
2024年、多くのAI研究者やCEOが「AGIは5年以内に実現する」と予測していました。Sam Altman、Demis Hassabis、Dario Amodeiなど、主要AI企業のリーダーが揃って楽観的な見通しを示しています。
しかし、CritPtは「現在のAIは大学院レベルの専門推論に遠く及ばない」という事実を突きつけました。
AGI定義とCritPtの矛盾:
AGIの一般的定義は「人間レベルの汎用知能」です。しかし、CritPtでAIモデルはPhD初年度学生の10分の1以下の能力しか示していません。これは、特定分野の専門性さえ獲得できていないことを意味します
| AGI実現の条件 | 現状(CritPt基準) | 達成度 |
|---|---|---|
| 大学レベルの知識 | ✅ MMLU 85%+ | 達成済み |
| 専門分野の深い理解 | ❌ CritPt 9.1% | 未達成 |
| 新規問題への推論 | ❌ 多くのモデルが0% | 未達成 |
| 研究レベルの創造性 | ❌ PhD学生の10分の1 | 未達成 |
特に重要なのは、「汎用性」の欠如です。
Gemini 3 Pro Previewは、RadLEベンチマーク(放射線医学)で51%を達成し、研修医の45%を超えました。しかし、CritPt(物理学)では9.1%に留まりました。これは、AIモデルが分野によって極端に性能が異なることを示しています。
- 医学画像診断:人間レベルに近い(RadLE 51%)
- コーディング:人間レベル(HumanEval 85%+)
- 大学レベル知識:人間超え(MMLU 85%+)
- 物理学研究:人間の10分の1以下(CritPt 9.1%)
これは、真の「汎用」知能ではないことを明確に示しています。
まとめ:AIの「知的天井」が見えた瞬間
CritPtベンチマークは、AI業界に謙虚さを取り戻させる可能性があります。
🔬 CritPtが明らかにした5つの真実
1. Gemini 3 Pro Previewが9.1%で「トップ」
- 最先端AIでも70問中6〜7問しか解けない
- 多くのモデルは5回試行しても0問
- 従来ベンチマークの「飽和」は幻想だった
2. PhD学生の10分の1以下の能力
- PhD初年度学生は70-85%の正答率と推定
- AIと人間の間に10倍以上の能力差
- 深い推論能力が決定的に欠如
3. 暗記では解けない新規問題
- 公開データに存在しない研究レベルの課題
- 60人以上の専門家が新規に作成
- 真の推論能力を測定する革新的設計
4. 11の物理学分野で一貫して失敗
- 量子物理学、天体物理学、流体力学など
- 分野横断的な知性の欠如を露呈
- 専門性と汎用性の両方で不十分
5. AGI到達は遥か遠い
- 「人間レベルの汎用知能」には程遠い
- 根本的なブレークスルーが必要
- 楽観的なAGI予測に現実的視点を提供
CritPtの最も重要なメッセージは、「AIは強力だが、まだ人間の知性には遠く及ばない」という現実です。
Gemini 3 Pro Previewは、RadLEで研修医を超え、MMLUで人間平均を上回りました。これらの成果は印象的です。しかし、CritPtは、「最先端物理学における真の大学院レベル推論」という基準では、AIはまだ入口にすら立っていないことを示しました。
| 評価軸 | 現状の到達点 | 人間レベルまでの道のり |
|---|---|---|
| 知識の広さ | ✅ 人間超え | 既に到達 |
| 知識の深さ | △ 部分的に人間レベル | 分野によって大きく異なる |
| 推論の深さ | ❌ 人間の10分の1以下 | 根本的ブレークスルー必要 |
| 研究能力 | ❌ ほぼゼロ | 全く到達していない |
今後、AIモデルがCritPtでどこまでスコアを伸ばせるかが、真のAGI進捗の指標となるでしょう。
9.1%から50%に到達する日が来たとき、私たちはAIが「人間レベルの科学的推論」に近づいたと言えるかもしれません。しかし、その日はまだ遠い未来の話です。

Gemini 3.0 Pro tops new physics benchmark at 9.1%
— Chubby♨️ (@kimmonismus) November 21, 2025
CritPt is a new graduate-level frontier physics benchmark built by over 60 researchers to test models on truly novel, research-grade problems across 11 physics subfields — and no current model scores above 9%.
Even top systems like Gemini 3 Pro Preview hit just 9.1%, underscoring how far today’s models still are from real post-grad reasoning in frontier physics. pic.twitter.com/bXos5O7QZA
Sources:
コメント