

AIの記憶領域に関して混乱している人が多そうなので「人の脳→AI」で整理します。
— 神威/KAMUI (@kamui_qai) February 26, 2024
・短期記憶→コンテキストウィンドウ
よく32kトークンとか、128kとか200kとか1Mとか10Mとか言われているアレ。
・長期記憶→ナレッジカットオフ
最近OpenAIのGPTは2023/12までの世界中の情報を学習しました。テストに出ます。
カットオフとは学習している最後の月のことで、サムアルトマン解任劇の事も覚えています。ただし国によって情報鮮度は優先度あり。日本の記憶は微妙(だった。5つ日ほど前の話です)
・外付け記憶(メモ帳)→RAG
厳密には外付け記憶から情報を引っ張り出してコンテキストウィンドウに入れて回答させるアーキテクチャの事をRAGと言いますが、一旦外付け記憶と思って頂ければ分かりやすいと思います。
最近Geminiが出てきたことによりRAG不要論が出て来ているのは、簡潔に言うと短期記憶が広がって外付け記憶いらないんじゃない?ということと同義です。カットオフが広がったことはRAG不要論の理由の1つになりますがコンテキストウィンドウのインパクトの方が大きいです。(アクセスできない会社の内部情報はカットオフが広がった所で情報源に出来ないため)
Geminiの短期記憶が今までの5(1Mトークン)〜50倍(10Mトークン、ただしリサーチ用途)になった事で、量→質転換の様な急激な精度上昇と短期記憶領域の超指数関数的な増加が見受けられる事から外付け記憶不要論は時間と共に増加すると思われます。(あくまで長期的な話で短期的には間違いなくRAGが必要です)
「AIの記憶ってどうなってるの?」 「コンテキストウィンドウって何?」 「RAGは本当に不要になるの?」
AI技術の進化が加速する中、 AIの記憶領域に関する混乱が広がっている。32kトークン、200k、1M、10M──数字が飛び交うが、その本質を理解している人は少ない。
この記事では、 人の脳との比較でAIの記憶領域を徹底的に整理する。
| 人の脳 | AIの対応機能 | 具体例 |
|---|---|---|
| 短期記憶 | コンテキストウィンドウ | 32k / 200k / 1M / 10Mトークン |
| 長期記憶 | ナレッジカットオフ | GPT: 2023年12月まで学習 |
| 外付け記憶(メモ帳) | RAG
(Retrieval Augmented Generation) |
Web検索、ベクトルDB、RDB |
この記事では、Geminiの 1000万トークンがもたらす革命、「RAG不要論」の真実、そして量→質転換の超指数関数的成長まで、AIの記憶アーキテクチャを完全解説する。
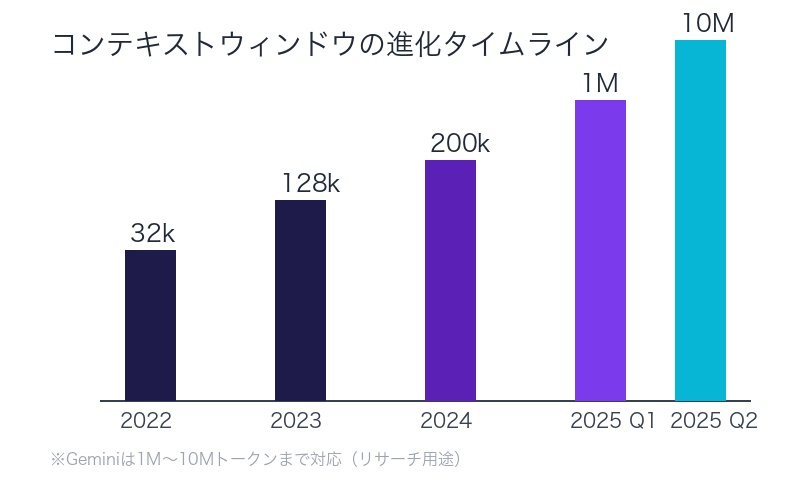
短期記憶=コンテキストウィンドウ:32k→200k→1M→10Mへの進化
コンテキストウィンドウとは:AIの「作業机の広さ」
コンテキストウィンドウは、AIが一度に処理できる情報量を示す。
人間で言えば、 「今この瞬間に頭の中で考えられる情報の範囲」──短期記憶に相当する。
「よく32kトークンとか、128kとか200kとか1Mとか10Mとか言われているアレ」
– 神威/KAMUI氏、X投稿より
「トークン」とは:文字数ではなく「意味の塊」
トークン(Token)は、AIが処理する「意味の最小単位」:
- 英語:1単語 ≈ 0.75トークン
- 日本語:1文字 ≈ 2-3トークン
トークン数の実例:
| トークン数 | 英語テキスト | 日本語テキスト | 具体例 |
|---|---|---|---|
| 32,000トークン | 約24,000単語 | 約10,000-16,000文字 | 小説1冊分 |
| 200,000トークン | 約150,000単語 | 約60,000-100,000文字 | 長編小説、技術書 |
| 1,000,000トークン | 約750,000単語 | 約300,000-500,000文字 | ハリー・ポッター全7巻 |
| 10,000,000トークン | 約7,500,000単語 | 約3,000,000-5,000,000文字 | 中規模図書館の蔵書 |
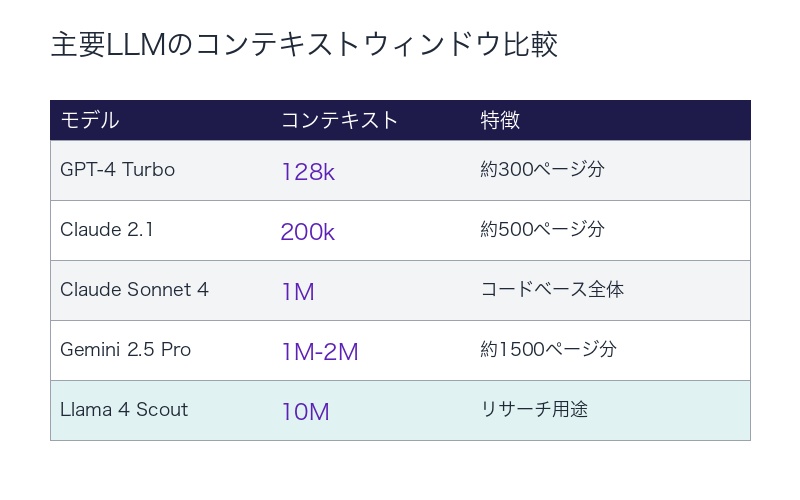
主要LLMのコンテキストウィンドウ比較(2025年)
| モデル | コンテキストウィンドウ | 特徴 |
|---|---|---|
| GPT-4 Turbo | 128,000トークン | 約300ページ分 |
| Claude 2.1 | 200,000トークン | 約500ページ分 |
| Claude Sonnet 4 | 1,000,000トークン | 2025年8月に拡大、コードベース全体を処理可能 |
| Gemini 2.5 Pro | 1,000,000~2,000,000トークン | 約1,500ページ分 |
| Meta Llama 4 Scout | 10,000,000トークン | リサーチ用途、最大級のコンテキスト |
コンテキストウィンドウ拡大のインパクト:5倍→50倍
神威/KAMUI氏が指摘するように:
「Geminiの短期記憶が今までの5(1Mトークン)〜50倍(10Mトークン、ただしリサーチ用途)になった事で、量→質転換の様な急激な精度上昇と短期記憶領域の超指数関数的な増加が見受けられる」
「量→質転換」とは:
- 量的変化:コンテキストウィンドウが5倍→50倍に拡大
- 質的変化:単なる処理量増加ではなく、理解の深さが根本的に向上
- 超指数関数的成長:直線的ではなく、加速度的に能力が向上
長期記憶=ナレッジカットオフ:GPTが2023年12月まで学習した世界
ナレッジカットオフとは:AIの「学んだ最後の日」
ナレッジカットオフ(Knowledge Cutoff)は、AIが学習した最後の時点を示す。
人間で言えば、 「人生で経験してきたすべての記憶」──長期記憶に相当する。
「最近OpenAIのGPTは2023/12までの世界中の情報を学習しました。テストに出ます」
「カットオフとは学習している最後の月のことで、サムアルトマン解任劇の事も覚えています」
– 神威/KAMUI氏、X投稿より
主要LLMのナレッジカットオフ日(2025年時点)
| モデル | ナレッジカットオフ | 覚えている出来事の例 |
|---|---|---|
| GPT-4 | 2023年4月 | ChatGPT初期の爆発的普及 |
| GPT-4o | 2023年10月 | Sam Altman解任前の状況 |
| GPT-4 Turbo | 2023年12月 | Sam Altman解任劇(2023年11月)を記憶 |

「国によって情報鮮度は優先度あり」の意味
神威/KAMUI氏が指摘する重要な点:
「ただし国によって情報鮮度は優先度あり。日本の記憶は微妙(だった。5つ日ほど前の話です)」
学習データの地域バイアス:
- 英語圏(米国・英国):最も豊富で最新
- 中国語圏:大量だが検閲の影響あり
- 日本語圏:相対的にデータ量が少なく、鮮度も劣る
なぜ日本の情報が微妙だったのか:
- 英語コンテンツの圧倒的優位性
- 日本語データの相対的少なさ
- OpenAIの学習優先度の影響
Web検索機能:カットオフを超える「リアルタイム記憶」
重要な注意点:
GPT-4oはWeb検索機能を備えており、ナレッジカットオフを超えたリアルタイム情報にアクセス可能。
これは何を意味するか:
- 長期記憶(ナレッジカットオフ):2023年10月
- 外付け記憶(Web検索):今日の情報まで取得可能
外付け記憶=RAG:3種類のデータベースとその未来
RAG(Retrieval Augmented Generation)とは
RAGは、人間で言えば「メモ帳やノート」に相当する。
「厳密には外付け記憶から情報を引っ張り出してコンテキストウィンドウに入れて回答させるアーキテクチャの事をRAGと言いますが、一旦外付け記憶と思って頂ければ分かりやすい」
– 神威/KAMUI氏、X投稿より
RAGの基本フロー:
- ユーザーが質問
- AIが外付け記憶(DB)から関連情報を検索
- 検索結果をコンテキストウィンドウに挿入
- コンテキスト+長期記憶で回答を生成
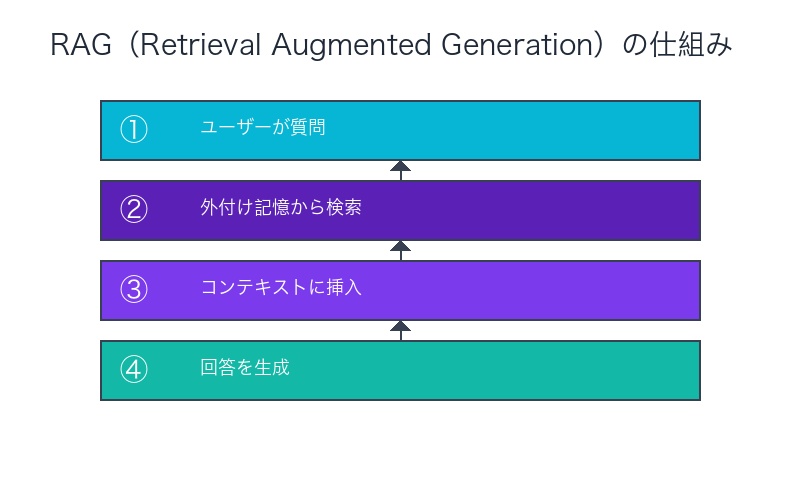
外付け記憶の3種類:Web情報、ベクトルDB、RDB
ちなみに外付け記憶を整理すると、
— 神威/KAMUI (@kamui_qai) February 26, 2024
・Web情報
・ベクトルデータベース
・RDB
の3つに分けられます。
Web情報に関してはコンテキストウィンドウ(長期記憶)のカットオフがつい最近まで近づいて来ているのでその重要性は下がりつつあります(もちろん昨日今日のことはweb検索重要)
ベクトルDBは簡単にいうとホワイトボードに付箋や写真やDVDをペタペタ貼り付けるタイプのデータベースです。似たカテゴリーのコンテンツは近くにまとめてあり、分かりやすくなっています。
Geminiが衝撃的だったのは、これまで付箋(テキスト)しか貼り付けられなかったのに、1時間レベルの動画を貼り付けることができる様になったこと。
私は流石に動画はRAG(外付け記憶)だろうと思っていたらあっという間に動画まで記憶し始めました。(内部的にRAG的な仕組みが使われている可能性はあり)
RDBはエクセルの様な縦横スタイルのDBですね。本棚をイメージしてください。ここはこれからも長いことコンテキストウィンドウに代替されないと、、私は信じています。
SQLなどクエリをLLMに吐き出させる仕組みですね。
こちらは検索型の仕組みで代替されるかもしれません。
①Web情報:重要性が下がりつつある外付け記憶
Web検索の役割:
- リアルタイム情報:昨日・今日の出来事
- カットオフ後の情報:学習データに含まれない最新情報
なぜ重要性が下がっているか:
| 要因 | 説明 |
|---|---|
| カットオフの近代化 | 2023年12月まで学習済み→ほぼ最新 |
| 更新頻度の向上 | 以前は数年遅れ→今は数ヶ月遅れ |
| Web検索統合 | LLM自身がWeb検索可能に |
「Web情報に関してはコンテキストウィンドウ(長期記憶)のカットオフがつい最近まで近づいて来ているのでその重要性は下がりつつあります(もちろん昨日今日のことはweb検索重要)」
②ベクトルデータベース:「ホワイトボードに付箋を貼る」
ベクトルDBの比喩:
「ベクトルDBは簡単にいうとホワイトボードに付箋や写真やDVDをペタペタ貼り付けるタイプのデータベースです。似たカテゴリーのコンテンツは近くにまとめてあり、分かりやすくなっています」
ベクトルDBの特徴:
- 意味的類似性で整理 – 似た内容が近くに配置される
- マルチモーダル – テキスト、画像、動画、音声すべて対応
- 柔軟な検索 – 「関連する情報を全部教えて」が可能
具体例:
| データ種類 | 従来のベクトルDB | Geminiのコンテキストウィンドウ |
|---|---|---|
| テキスト | ✅ 対応(付箋) | ✅ 100万~200万トークン |
| 画像 | ✅ 対応(写真) | ✅ 大量処理可能 |
| 動画 | △ 限定的(DVD) | ✅ 1時間レベルの動画を直接処理 |
Geminiの衝撃:1時間動画をコンテキストウィンドウに直接投入
「Geminiが衝撃的だったのは、これまで付箋(テキスト)しか貼り付けられなかったのに、1時間レベルの動画を貼り付けることができる様になったこと」
「私は流石に動画はRAG(外付け記憶)だろうと思っていたらあっという間に動画まで記憶し始めました」
これは何を意味するか:
- 従来:動画をテキスト化→ベクトルDBに保存→検索→コンテキストに挿入
- Gemini:動画を直接コンテキストウィンドウに投入→即座に理解

③RDB(リレーショナルデータベース):「本棚」の記憶
RDBの比喩:
「RDBはエクセルの様な縦横スタイルのDBですね。本棚をイメージしてください」
「ここはこれからも長いことコンテキストウィンドウに代替されないと、、私は信じています」
RDBの特徴:
- 構造化されたデータ – テーブル(表)形式
- 正確な検索 – SQLクエリで厳密に抽出
- 大規模データ – 数億~数兆レコード
なぜコンテキストウィンドウに代替されないのか:
- スケールの問題 – 企業データは1000万トークンでも収まらない
- 精度の問題 – LLMは「大体合ってる」、RDBは「完全一致」
- リアルタイム更新 – RDBは瞬時に更新、コンテキストは固定
| 要求 | RDB | コンテキストウィンドウ |
|---|---|---|
| 「2025年10月の売上合計は?」 | ✅ 完璧な精度 | △ おおよその値 |
| 「売上が多い月の傾向を教えて」 | △ 集計のみ | ✅ 洞察提供 |
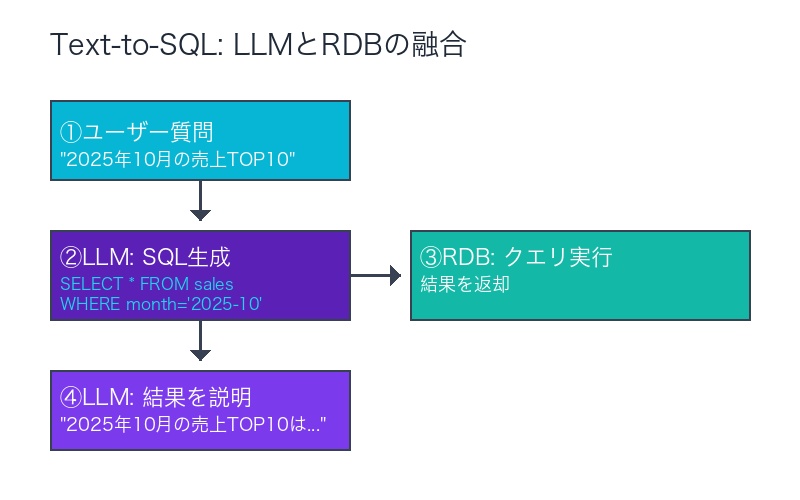
RDBとLLMの融合:Text-to-SQL
「SQLなどクエリをLLMに吐き出させる仕組みですね」
「こちらは検索型の仕組みで代替されるかもしれません」
Text-to-SQLの仕組み:
- ユーザー:「2025年10月の売上TOP10を教えて」
- LLM:SQL生成 `SELECT * FROM sales WHERE month=’2025-10′ ORDER BY amount DESC LIMIT 10`
- RDB:クエリ実行→結果返却
- LLM:結果を自然言語で説明
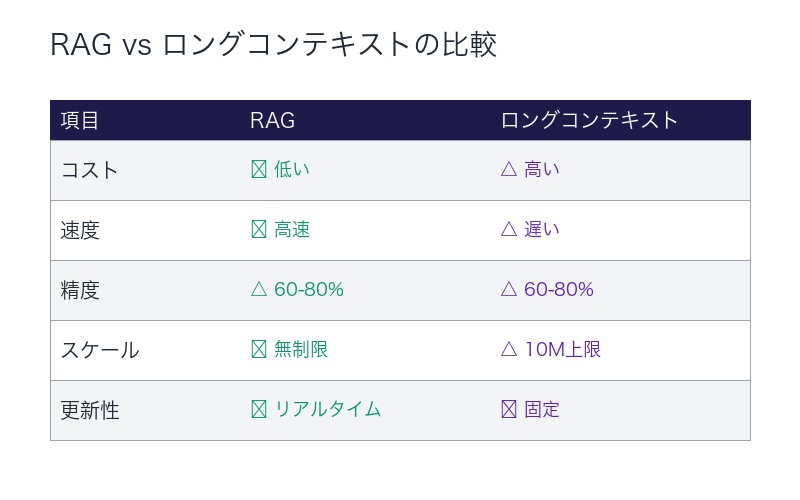
RAG不要論の真実:Geminiの衝撃とその限界
「10Mコンテキストが RAGを殺す」発言の衝撃
「最近Geminiが出てきたことによりRAG不要論が出て来ているのは、簡潔に言うと短期記憶が広がって外付け記憶いらないんじゃない?ということと同義です」
著名AI研究者 Dr. Yao Fu氏は、Gemini 1.5 Proのレビューで大胆に述べた:
「The 10M context kills RAG」
(1000万トークンのコンテキストがRAGを殺す)– Dr. Yao Fu、Twitter投稿より
RAG不要論の2つの根拠
①コンテキストウィンドウ拡大の影響(主要因)
「カットオフが広がったことはRAG不要論の理由の1つになりますがコンテキストウィンドウのインパクトの方が大きいです」
「(アクセスできない会社の内部情報はカットオフが広がった所で情報源に出来ないため)」
なぜコンテキストウィンドウが重要か:
- ナレッジカットオフ拡大:2020年→2023年(+3年) – 有用だが限定的
- コンテキストウィンドウ拡大:200k→1M→10M(+50倍) – 革命的変化
企業の内部情報はカットオフに含まれない:
- OpenAIは一般公開データのみ学習
- 企業の非公開データ(契約書、財務諸表、社内文書)は永遠にカットオフに含まれない
- → コンテキストウィンドウに直接投入すれば解決
②ナレッジカットオフの近代化(副次的要因)
| 年代 | ナレッジカットオフ | 現在との差 |
|---|---|---|
| GPT-3(2020年) | 2019年 | 6年遅れ |
| GPT-4(2023年) | 2023年4月 | 2年遅れ |
| GPT-4 Turbo(2025年) | 2023年12月 | 1年遅れ |
業界の総意:RAGは依然として必要
しかし、 業界専門家の圧倒的総意は:
「RAGは死んでいない。むしろ進化している」
RAGが依然として必要な4つの理由
①コスト効率
- 1000万トークンのコンテキストは非常に高価
- RAGは必要な情報のみ検索→コスト大幅削減
②レイテンシー(応答速度)
- 1000万トークン処理は時間がかかる
- RAGは関連情報のみ提供→即座に回答
③精度とリコール率
Googleの調査:Gemini 1.5は100万トークンに近づくとリコール率が0.8未満に低下
「60-80%では不十分。LLMはコンテキストウィンドウ内の情報を十分に活用できても、最大40%の情報を失う」
④スケールとリアルタイム性
- Google検索インデックス規模:どんなLLMでも収容不可能
- 企業の内部データ:所有者の管理下に留まる必要がある
- リアルタイム更新:コンテキストは固定、RAGは常に最新
Geminiの特殊性:RAGなしでも動くケース
興味深い発見:
調査結果:RAGはGPT-4とCommand R+のパフォーマンスを大幅に改善するが、Claude 3 Opus、Mixtral 8x7B、Gemini 1.5 Proにはほとんど影響しない
なぜGeminiはRAGなしでも動くのか:
- 超長コンテキストウィンドウ(100万~200万トークン)
- マルチモーダル(テキスト・画像・動画同時処理)
- 優れた長距離依存性の理解
神威/KAMUI氏の結論:短期的にはRAG必要、長期的には減少
「外付け記憶不要論は時間と共に増加すると思われます。(あくまで長期的な話で短期的には間違いなくRAGが必要です)」
| 期間 | RAGの必要性 | 理由 |
|---|---|---|
| 短期(現在~3年) | 間違いなく必要 | コスト、精度、スケール、企業データ管理 |
| 中期(3~7年) | 徐々に減少 | コンテキストウィンドウ100M~1Bトークンへ拡大 |
| 長期(7年~) | 大幅減少 (ただしRDBは残存) |
超大規模コンテキスト、リアルタイム学習 |
量→質転換の超指数関数的成長:何が起きているのか
「量→質転換」の意味
「Geminiの短期記憶が今までの5(1Mトークン)〜50倍(10Mトークン、ただしリサーチ用途)になった事で、量→質転換の様な急激な精度上昇と短期記憶領域の超指数関数的な増加が見受けられる」
量的変化:
- 200kトークン → 1Mトークン = 5倍
- 200kトークン → 10Mトークン = 50倍
質的変化(量→質転換):
- 単なる「処理できる文字数が増えた」ではない
- 理解の深さが根本的に向上
- 新しい能力の出現(Emergent Abilities)
具体例:1時間動画の完全理解
200kトークン時代:
- 動画を文字起こし
- テキストを要約(200k以内に収める)
- 要約テキストをコンテキストに投入
- → 詳細は失われる
10Mトークン時代(Gemini):
- 動画を直接投入
- 映像・音声・文字すべてを理解
- → 完全な文脈理解
超指数関数的成長とは
線形成長: 1, 2, 3, 4, 5… 指数関数的成長: 1, 2, 4, 8, 16, 32… 超指数関数的成長: 1, 2, 4, 16, 256, 65536…
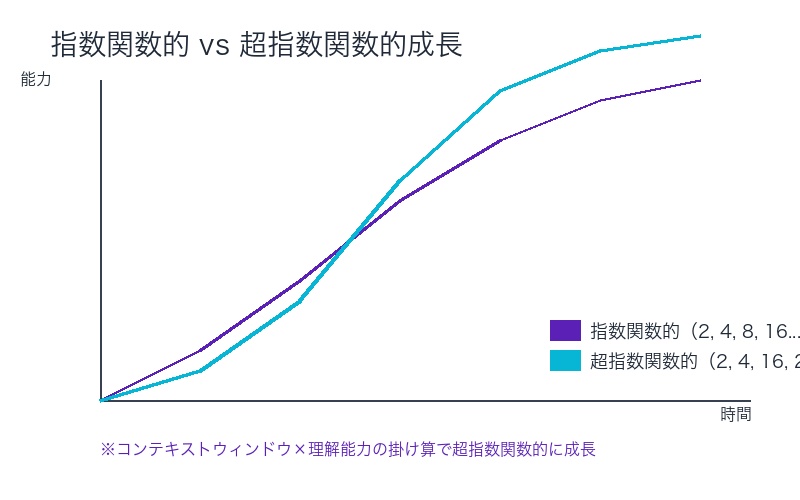
なぜ超指数関数的なのか:
- コンテキスト×理解能力の掛け算
- コンテキストが10倍 × 理解能力が10倍 = 100倍の効果
- 新しい能力の連鎖的出現
まとめ:AIの記憶領域の全体像と未来
| 記憶種類 | AI機能 | 現状 | 未来 |
|---|---|---|---|
| 短期記憶 | コンテキストウィンドウ | 200k→1M→10M 超指数関数的拡大 |
100M~1Bトークン 動画・音声完全統合 |
| 長期記憶 | ナレッジカットオフ | 2023年12月 1年遅れ |
リアルタイム学習 常時更新 |
| 外付け記憶 | RAG | Web検索、ベクトルDB、RDB 短期的に必須 |
長期的に減少 RDBは残存 |
3つの重要な洞察
①コンテキストウィンドウ拡大が最重要
- カットオフ拡大よりインパクトが大きい
- 企業の内部データをカバーできる
- 量→質転換を引き起こす
②RAGは短期的に必須、長期的に減少
- コスト、精度、スケールの観点で現在は不可欠
- 1000万→1億→10億トークン時代に徐々に役割縮小
- RDBは長く残る(構造化データの精度要求)
③Geminiの革命:動画まで記憶
- 「付箋(テキスト)」→「1時間動画」まで拡大
- ベクトルDBの一部をコンテキストウィンドウが代替
- マルチモーダル統合の新時代
実践的アドバイス:AIエンジニアへの指針
短期戦略(現在~3年):
- RAGを適切に実装 – コスト効率と精度のバランス
- コンテキストウィンドウを最大活用 – 1Mトークンを前提に設計
- ハイブリッドアプローチ – RAG+長コンテキストの組み合わせ
長期戦略(3年~):
- コンテキストファースト設計への移行準備
- RDBとの統合は継続投資
- リアルタイム学習機能の活用準備
最後に:AIの記憶は人を超えるか
現時点の答え:一部で既に超えている
| 能力 | 人間 | AI(Gemini 10M) |
|---|---|---|
| 短期記憶容量 | 7±2項目 | 1000万トークン
(本数百冊分) |
| 長期記憶の正確性 | 曖昧、変化する | 完璧に保持 |
| 文脈理解 | 優れている | 急速に向上中 |
| 創造性 | 依然として優位 | 模倣は可能 |
AIの記憶領域は、もはや「人の脳の模倣」ではない。
1000万トークンのコンテキストウィンドウ、リアルタイムWeb検索、完璧な長期記憶── AIは人間とは異なる形で、独自の「知性」を獲得しつつある。
この記事で整理した3つの記憶(短期・長期・外付け)の理解が、 AI時代を生き抜く基礎知識となるだろう。
コメント