

大規模言語モデル(LLM)のトレーニングは、AI開発における最も複雑で挑戦的なタスクの1つです。データの準備から事前学習、事後学習、インフラの構築まで、あらゆる段階で専門的な知識と実践的なノウハウが必要とされます。
2025年10月31日、Hugging Faceの事前学習チームが、この課題に応えるべく200ページに及ぶ「Smol Training Playbook」を公開しました。このガイドは、LLMトレーニングの全段階を詳細に解説し、実際の開発現場で得られた教訓、デバッグのヒント、そして大規模トレーニングで実際に効果的な手法を網羅しています。
本記事では、Smol Training Playbookの内容を徹底解説するとともに、関連するUltra-Scale Playbook(4000以上のスケーリング実験)とSmol Course(実践的学習プログラム)についても紹介します。LLM開発に携わる研究者やエンジニアにとって、必見のリソース情報をお届けします。
Smol Training Playbookとは?200ページの包括的ガイド
Smol Training Playbookは、Hugging Faceの事前学習チーム(Hugging Face Smol Models Research)が公開した、LLMトレーニングの完全実践ガイドです。「The Secrets to Building World-Class LLMs(世界クラスのLLMを構築する秘訣)」というサブタイトルが示すように、実務で即座に活用できる実践的な内容が特徴です。
このプレイブックは、Hugging Face Spacesで無料公開されており、誰でもアクセス可能です。200ページという圧倒的なボリュームで、以下のような特徴があります。
- 包括的なカバレッジ:データ準備、事前学習、事後学習、インフラ構築の全段階を網羅
- 実践的な洞察:実際のプロジェクトで得られた教訓とベストプラクティス
- デバッグガイド:よくある問題とその解決方法を詳細に解説
- 効果検証済み:大規模トレーニングで実際に効果が確認された手法のみを紹介
X(旧Twitter)での投稿は、公開から24時間で89いいね、15リツイート、60ブックマークを獲得し、AI研究コミュニティから高い関心を集めています。

カバーされる主要トピック:データ準備から事後学習まで
Smol Training Playbookは、LLMトレーニングのライフサイクル全体を4つの主要領域に分けて解説しています。それぞれの領域で、理論と実践の両面から詳細なガイダンスを提供します。
1. データ準備(Data Preparation)
高品質なLLMを構築するには、適切なデータセットの準備が不可欠です。この領域では、以下のトピックをカバーしています。
- データセットの設計原則と選択基準
- データクリーニングと品質管理の実践
- トークン化と前処理のベストプラクティス
- データの多様性とバイアス対策
- 大規模データセットの効率的な管理
2. 事前学習(Pre-training)
事前学習は、LLMの基礎能力を構築する最も重要な段階です。プレイブックでは、モデルアーキテクチャの選択から最適化手法まで、詳細に解説しています。
- トランスフォーマーアーキテクチャの設計選択
- 学習率スケジューリングと最適化アルゴリズム
- バッチサイズと勾配累積の調整
- 混合精度トレーニングの実装
- トレーニングの安定性とモニタリング
3. 事後学習(Post-training)
事前学習されたモデルを、特定のタスクやユースケースに適応させる段階です。ファインチューニングやアライメント技術について解説しています。
- 教師あり微調整(Supervised Fine-tuning)の戦略
- 強化学習による人間のフィードバックからの学習(RLHF)
- DPO(Direct Preference Optimization)などの最新手法
- モデルのアライメントと安全性の確保
4. インフラストラクチャ(Infrastructure)
大規模LLMのトレーニングには、適切なインフラ設計が不可欠です。GPU設定から分散学習まで、実践的な知識を提供します。
- GPU環境の最適化とリソース管理
- 分散学習システムの構築
- トレーニングパイプラインの自動化
- パフォーマンス監視とトラブルシューティング
実践的な洞察とデバッグのヒントが満載
Smol Training Playbookの最大の価値は、実際のプロジェクトで得られた教訓を惜しみなく共有している点にあります。理論的な説明だけでなく、現場で直面する具体的な問題とその解決策を提示しています。
学んだ教訓(Lessons Learned)
プレイブックには、Hugging Faceチームが数多くのLLMトレーニングプロジェクトを通じて獲得した貴重な知見が含まれています。
- 効果的だった手法とその理由
- 失敗した実験から得られた洞察
- コスト削減とリソース最適化のテクニック
- スケールアップ時の落とし穴と回避策
デバッグのヒント(Debugging Tips)
LLMトレーニング中に遭遇する典型的な問題について、体系的なデバッグ手法を紹介しています。
- 損失が収束しない場合の診断方法
- メモリ不足エラーの解決策
- 勾配爆発・消失問題への対処
- トレーニングの不安定性の原因特定
- 分散学習環境でのデバッグ戦略
何が実際に効果的か(What Actually Works)
プレイブックは、理論と実践のギャップを埋めることに重点を置いています。学術論文で提案された手法の中で、実際の大規模トレーニングで効果が確認されたものを明確にしています。
| カテゴリ | 効果的な手法 | 注意点 |
|---|---|---|
| 最適化 | AdamW、学習率ウォームアップ | ハイパーパラメータ調整が重要 |
| 正則化 | ドロップアウト、重み減衰 | 過剰な正則化は性能低下を招く |
| スケーリング | データ並列化、勾配累積 | バッチサイズとの適切なバランス |
| メモリ最適化 | 混合精度、勾配チェックポイント | 速度とメモリのトレードオフ |

Ultra-Scale Playbook:4000以上の実験から得られた知見
Smol Training Playbookと並んで、Hugging Faceは2025年3月に「Ultra-Scale Playbook: Training LLMs on GPU Clusters」も公開しています。このガイドは、GPUクラスターでのLLMトレーニングに特化した内容で、Smol Training Playbookを補完する形で活用できます。
驚異的な実験規模
Ultra-Scale Playbookは、4000以上のスケーリング実験を実施し、最大512台のGPUを使用してテストされた結果に基づいています。この規模の実験から得られたデータは、LLMトレーニングの最適化において極めて貴重です。
- 実験総数:4000以上
- 最大GPU数:512台
- 焦点:スループット最適化、GPU利用率向上、トレーニング効率
実証済みの最適化手法
InfoQの報道によれば、Ultra-Scale Playbookは以下のような実績を報告しています。
- GPU利用率:最適な並列化設定により、90%以上の利用率を達成
- トレーニング時間:適切なスケーリング戦略により、大幅な時間短縮を実現
- コスト効率:リソースの最適配分により、トレーニングコストを削減
SmolとUltra-Scaleの使い分け
2つのプレイブックは相互補完的な関係にあります。
- Smol Training Playbook:LLMトレーニングの全体像と基礎を学ぶ
- Ultra-Scale Playbook:大規模GPU環境での実装と最適化に特化
小規模なプロジェクトから始める場合はSmol Training Playbookを、本格的なスケールアップを計画する際にはUltra-Scale Playbookを参照することで、効率的な学習と実装が可能になります。
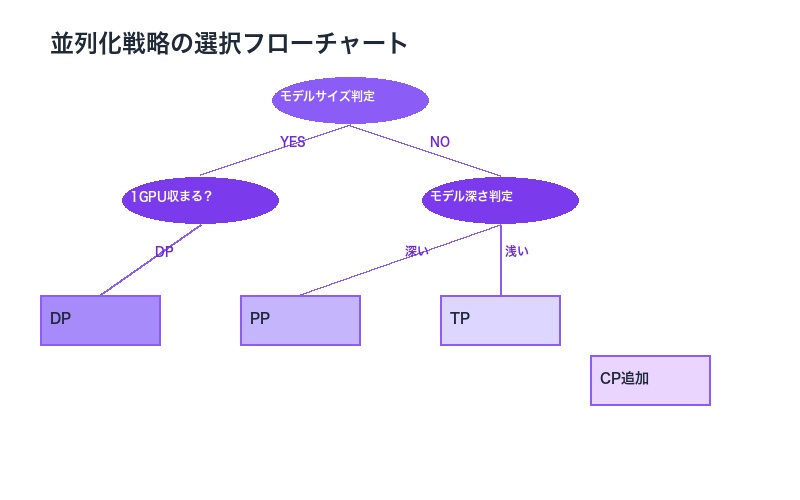
並列化戦略の詳細解説:DP、TP、PPの実践
Ultra-Scale Playbookでは、大規模LLMトレーニングに不可欠な並列化戦略について詳細に解説しています。これらの技術は、512台のGPUを効率的に活用するための鍵となります。
1. データ並列化(Data Parallelism: DP)
データ並列化は、最も基本的な並列化手法です。複数のGPUが異なるデータバッチを同時に処理し、勾配を集約します。
- メリット:実装が比較的簡単、小規模モデルに最適
- 課題:モデル全体が各GPUのメモリに収まる必要がある
- 適用場面:モデルサイズが1つのGPUメモリに収まる場合
2. テンソル並列化(Tensor Parallelism: TP)
テンソル並列化は、モデルの重み(パラメータ)をGPU間に分散します。大規模モデルのトレーニングに不可欠な技術です。
- メリット:超大規模モデルのトレーニングが可能
- 課題:GPU間の通信オーバーヘッドが発生
- 適用場面:モデルサイズが1つのGPUメモリを超える場合
3. パイプライン並列化(Pipeline Parallelism: PP)
パイプライン並列化は、モデルを複数のセグメントに分割し、異なるGPUに配置します。各GPUが異なるレイヤーを担当します。
- メリット:メモリ効率が高い、深いモデルに適している
- 課題:バブル時間(アイドル時間)の最小化が必要
- 適用場面:非常に深いモデルのトレーニング
4. コンテキスト並列化(Context Parallelism: CP)
最新の技術として、コンテキスト並列化がUltra-Scale Playbookで紹介されています。長いコンテキスト長を持つモデルのスケーラビリティを向上させます。
| 並列化手法 | 主な用途 | GPU間通信 | 実装難易度 |
|---|---|---|---|
| データ並列化(DP) | 小~中規模モデル | 低 | 低 |
| テンソル並列化(TP) | 超大規模モデル | 高 | 中 |
| パイプライン並列化(PP) | 深いモデル | 中 | 高 |
| コンテキスト並列化(CP) | 長コンテキストモデル | 中 | 高 |
メモリ最適化テクニック
並列化と並んで重要なのが、メモリ最適化です。Ultra-Scale Playbookでは、以下の技術を推奨しています。
- 活性化値の再計算(Activation Recomputation):メモリ使用量を削減し、より大きなバッチサイズでトレーニング可能に
- 勾配累積(Gradient Accumulation):メモリ制限を超えずに、大きな実効バッチサイズを実現
- 混合精度トレーニング:FP16やBF16を使用してメモリ使用量を半減
Smol Course:実践的な学習プログラム
Hugging Faceは、理論と実践を橋渡しするSmol Courseも提供しています。このコースは、小規模言語モデルの調整に関する実践的なプログラムで、GPUの要件が最小限で、有料サービスは不要という特徴があります。
コースの特徴
- ローカル実行可能:自分のマシンで実行できる
- 最小限のGPU要件:高性能GPUがなくても学習可能
- 無料:有料のクラウドサービスは不要
- 実践重視:理論だけでなく、実装スキルを習得
7つのユニット構成
Smol Courseは、以下の7つのユニットで構成されています(2025年11月現在)。
- 指示調整(Instruction Tuning)✅ – 教師あり微調整とチャットテンプレート
- 評価(Evaluation)✅ – ベンチマークとカスタムドメイン評価
- 選好アライメント(Preference Alignment)✅ – DPOなどのアルゴリズムを使用
- ビジョン言語モデル(Vision Language Models)✅ – マルチモーダルモデルの適応
- 強化学習(Reinforcement Learning)(2025年10月公開予定) – 強化学習ポリシーに基づく最適化
- 合成データ(Synthetic Data)(2025年11月公開予定) – カスタムドメイン用データセット生成
- 授賞式(Capstone)(2025年12月公開予定) – プロジェクト展示とコミュニティ表彰
対象読者と前提知識
Smol Courseは、以下のような学習者を想定しています。
- 機械学習とNLPの基本的な理解がある
- Python、PyTorch、Transformersライブラリに精通している
- LLMの微調整やアライメントを実践的に学びたい
使用モデル
コースでは、SmolLM3およびSmolVLM2を中心に扱いますが、学習した技能はより大規模なモデルにも応用可能です。これにより、小規模環境で学習し、実務では大規模モデルに適用するというステップアップが可能になります。
| ユニット | 主要トピック | 実践スキル | 公開状況 |
|---|---|---|---|
| 1. 指示調整 | 教師あり微調整 | チャットボット構築 | ✅ |
| 2. 評価 | ベンチマーク評価 | モデル性能測定 | ✅ |
| 3. 選好アライメント | DPO実装 | 人間の好みに合わせた調整 | ✅ |
| 4. ビジョン言語モデル | マルチモーダル学習 | 画像とテキストの統合 | ✅ |
| 5. 強化学習 | RLHF | 報酬モデルの構築 | 2025年10月 |
| 6. 合成データ | データ生成 | カスタムデータセット作成 | 2025年11月 |
| 7. 授賞式 | プロジェクト統合 | 実務レベルの実装 | 2025年12月 |
誰がこのリソースを活用すべきか?
Hugging Faceが提供するこれらのリソース(Smol Training Playbook、Ultra-Scale Playbook、Smol Course)は、LLM開発に携わる幅広い層に価値を提供します。
研究者(Researchers)
- 最新のトレーニング手法と実験結果を参照できる
- 4000以上の実験データから得られた知見を研究に活用
- 実装の詳細を理解し、再現性の高い研究を実施
機械学習エンジニア(ML Engineers)
- 実務で即座に活用できる実践的なガイダンス
- デバッグとトラブルシューティングの具体的な手法
- 大規模トレーニングのインフラ設計と最適化
スタートアップとAI企業
- コスト効率の高いトレーニング戦略
- 小規模から大規模へのスケールアップ手法
- リソース最適化による開発期間の短縮
学生と学習者
- 体系的なLLMトレーニングの学習
- Smol Courseによる実践的なスキル習得
- 無料リソースによる低コストな学習
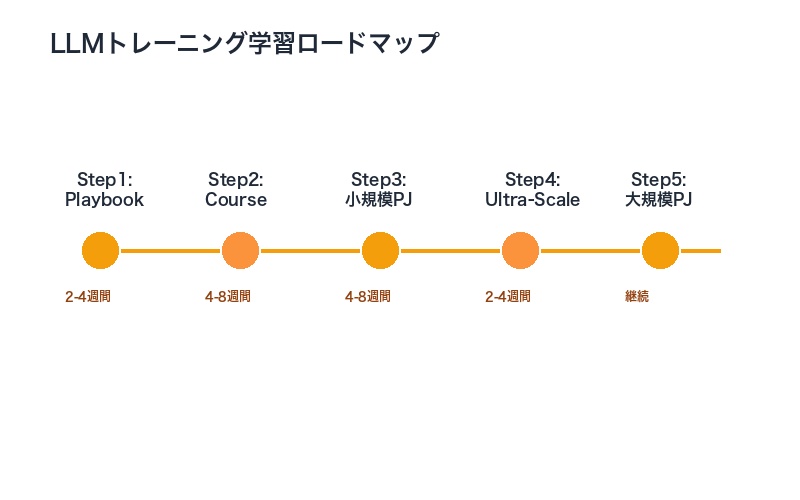
推奨される学習パス
- 基礎学習:Smol Training Playbookで全体像を把握
- 実践トレーニング:Smol Courseで小規模モデルを使って実装スキルを習得
- スケールアップ:Ultra-Scale Playbookで大規模環境への展開方法を学習
- 継続的改善:プロジェクトで得た知見をコミュニティにフィードバック
まとめ:Hugging Faceの包括的なLLMトレーニングエコシステム
Hugging Faceが提供するSmol Training Playbook、Ultra-Scale Playbook、Smol Courseは、LLMトレーニングの学習から実践まで、包括的にサポートする強力なエコシステムを形成しています。
主要なポイント
- 200ページの詳細ガイド:Smol Training Playbookは、データ準備から事後学習まで全段階をカバー
- 4000以上の実験結果:Ultra-Scale Playbookは、最大512台のGPUを使用した実証済みの知見を提供
- 実践的な学習プログラム:Smol Courseは、7つのユニットで段階的にスキルを習得
- 無料でアクセス可能:すべてのリソースがHugging Face Spacesで無料公開
今すぐ始められるアクション
- Smol Training Playbookをダウンロードし、自分のプロジェクトに関連する章から読み始める
- Smol Courseに登録し、指示調整(Unit 1)から実践的なトレーニングを開始
- Ultra-Scale Playbookで並列化戦略を学び、スケールアップの準備を行う
- Hugging Faceコミュニティに参加し、他の学習者や研究者と知見を共有
LLMトレーニングは複雑で挑戦的なタスクですが、Hugging Faceが提供するこれらのリソースを活用することで、効率的かつ効果的に学習し、実践することが可能になります。2025年は、LLMトレーニングの民主化が加速する年となるでしょう。
関連リンク
- Smol Training Playbook: https://huggingface.co/spaces/HuggingFaceTB/smol-training-playbook
- Ultra-Scale Playbook: https://huggingface.co/spaces/nanotron/ultrascale-playbook
- Smol Course: https://huggingface.co/learn/smol-course/unit0/1
- Hugging Face GitHub: https://github.com/huggingface/smol-course
あなたのLLMトレーニングプロジェクトの成功を、これらの実践的なリソースが強力にサポートします。今すぐアクセスして、世界クラスのLLM構築の旅を始めましょう。
コメント