

ロボットAIの世界に、新たな基盤モデルが登場した。
中国のRobbyant社が発表した「LingBot-VLA」は、約2万時間の実世界ロボット操作データで訓練されたVision-Language-Action(VLA)基盤モデルだ。9種類の主流デュアルアームロボット構成に対応し、既存のVLAモデルを大幅に上回る性能を実現している。
注目すべきは、コード、基本モデル、ベンチマークデータがすべてオープンソースで公開されている点だ。

LingBot-VLAとは:実世界スケーリング則の実証
Vision-Language-Action(VLA)モデルとは、視覚情報と言語指示を理解し、ロボットの動作(アクション)を生成する統合AIモデルだ。LingBot-VLAは、この分野で初めて「実世界スケーリング則」を体系的に実証した。

| 項目 | 数値 |
|---|---|
| 訓練データ量 | 約20,000時間 |
| 対応ロボット構成 | 9種類(デュアルアーム) |
| 評価タスク数 | 100タスク × 3プラットフォーム |
| タスクあたりのエピソード数 | 130エピソード |
| 訓練スループット | 261サンプル/秒(8GPU) |
実世界スケーリング則:データ量と性能の関係
LingBot-VLAの最も重要な発見は、VLAモデルにおける実世界スケーリング則の実証だ。
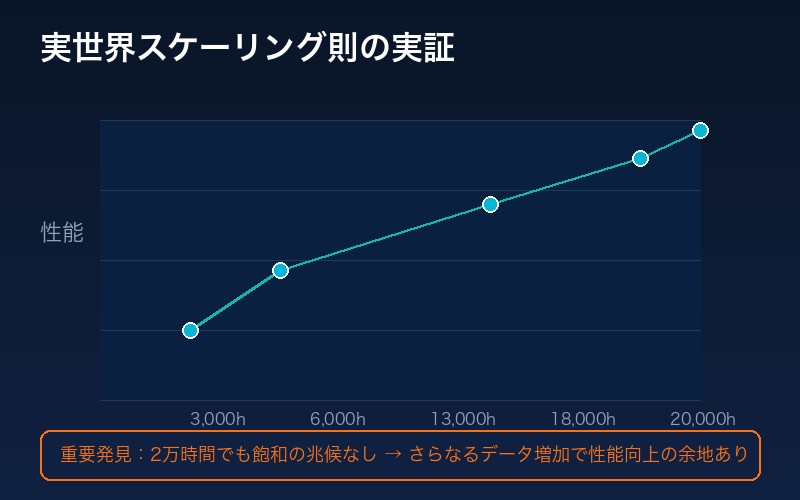
訓練データを3,000時間から段階的に増加させた実験結果:
| 訓練データ量 | 性能向上 |
|---|---|
| 3,000時間 | ベースライン |
| 6,000時間 | ↑ 継続的向上 |
| 13,000時間 | ↑ 継続的向上 |
| 18,000時間 | ↑ 継続的向上 |
| 20,000時間 | ↑ まだ飽和の兆候なし |
重要な発見:
2万時間の段階でも性能向上に飽和の兆候が見られない。VLAモデルはさらなるデータ増加から恩恵を受け続ける可能性が高い。
3つのロボットプラットフォームでの実機評価
LingBot-VLAは、3種類の異なるロボットプラットフォームで大規模な実機評価を実施した:
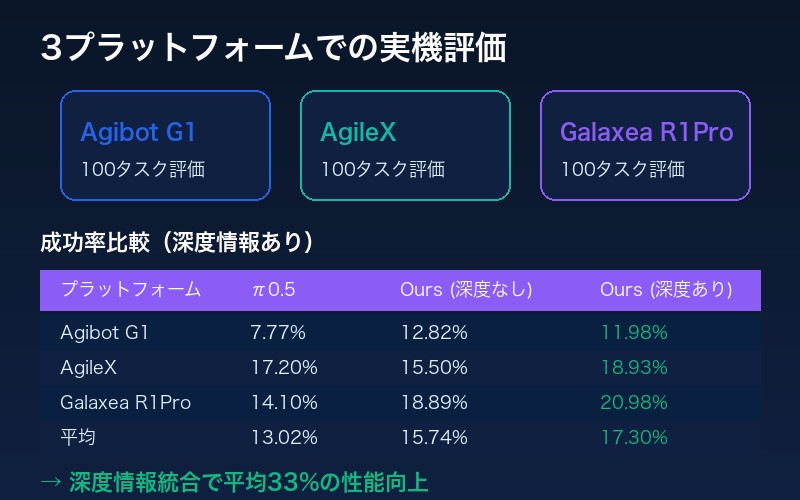
- Agibot G1
- AgileX
- Galaxea R1Pro
実機評価結果(深度情報あり/なし比較)
| プラットフォーム | π0.5 (SR) | Ours w/o depth | Ours w/ depth |
|---|---|---|---|
| Agibot G1 | 7.77% | 12.82% | 11.98% |
| AgileX | 17.20% | 15.50% | 18.93% |
| Galaxea R1Pro | 14.10% | 18.89% | 20.98% |
| 平均 | 13.02% | 15.74% | 17.30% |
深度情報を統合したバージョンでは、平均成功率がπ0.5の13.02%から17.30%へと約33%向上している。
高効率な訓練コードベース
LingBot-VLAのもう一つの大きな貢献は、高効率な訓練インフラだ。

| 指標 | LingBot-VLA | 既存VLAコードベース |
|---|---|---|
| スループット(8GPU) | 261サンプル/秒 | 93-174サンプル/秒 |
| 高速化倍率 | 1.5〜2.8倍 | ベースライン |
この高効率化は以下の技術によって実現されている:
- FSDP(Fully Sharded Data Parallel)
- 混合精度訓練
- オペレータ融合
深度認識によるロボット操作の強化
LingBot-VLAは、LingBot-Depthとの統合により、深度情報を活用した操作が可能だ。

シミュレーション評価結果
| シーン | π0.5 | Ours w/o depth | Ours w/ depth |
|---|---|---|---|
| クリーンシーン | 82.74% | 86.50% | 88.56% |
| ランダム化シーン | 76.76% | 85.34% | 86.68% |
特に注目すべきは、深度情報により透明な物体(ガラス花瓶など)の認識・操作が可能になった点だ。
効率的な下流タスクへの適応
大規模な事前訓練により、LingBot-VLAは少ないデータで新しいタスクに適応できる。
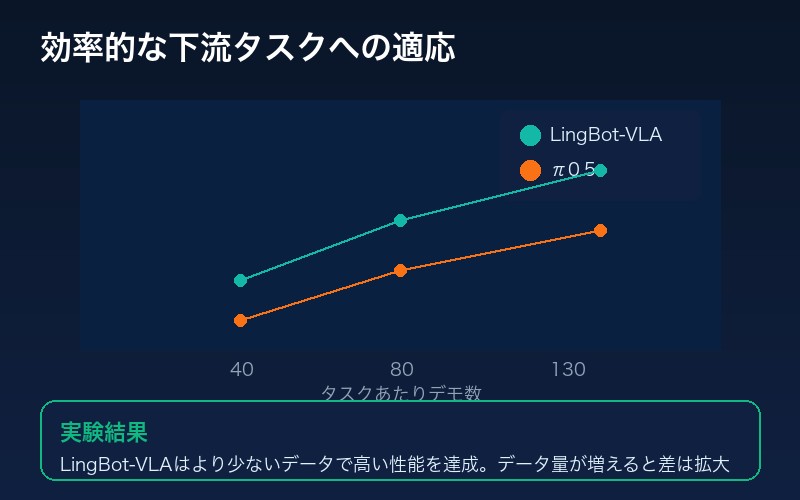
実験結果:
LingBot-VLAはπ0.5と比較して、より少ないデータで高い性能を達成。データ量が増えるほど、この性能差はさらに拡大する。
オープンソース公開:コード・モデル・データセット
LingBot-VLAは、ロボット学習分野の発展のため、すべてをオープンソースで公開している:

| リソース | 内容 | リンク |
|---|---|---|
| コード | 訓練・推論コードベース | GitHub |
| モデル(4B) | lingbot-vla-4b | Hugging Face |
| モデル(4B + depth) | lingbot-vla-4b-depth | Hugging Face |
| データセット | lingbot-GM-100 | Hugging Face |
Robbyantのエコシステム
LingBot-VLAは、Robbyantが展開するロボットAIエコシステムの一部だ:
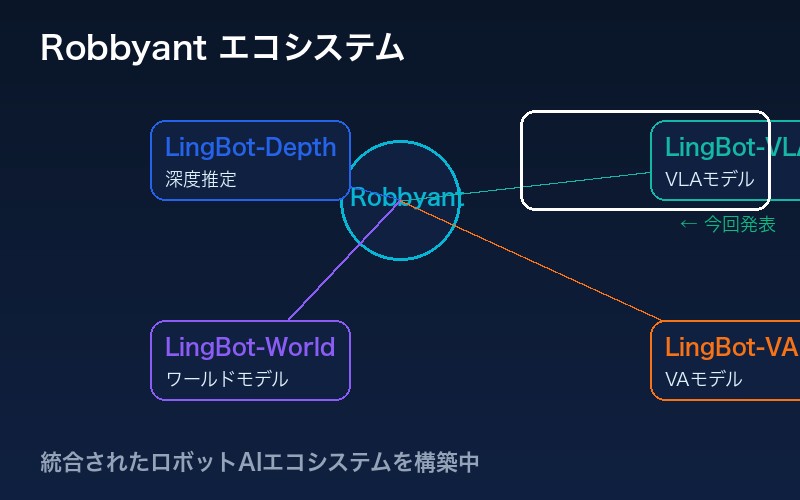
- LingBot-Depth:深度推定モデル
- LingBot-VLA:Vision-Language-Actionモデル(今回発表)
- LingBot-World:ワールドモデル
- LingBot-VA:Vision-Actionモデル
まとめ:ロボットAI基盤モデルの新時代
LingBot-VLAは、以下の点でロボットAI分野における重要なマイルストーンとなる:

- 実世界スケーリング則の実証:2万時間でも飽和せず、さらなるデータ増加の価値を示唆
- 高効率な訓練基盤:既存の1.5〜2.8倍の訓練効率
- マルチプラットフォーム対応:9種類のデュアルアーム構成に対応
- 完全オープンソース:コード、モデル、データセットを公開
中国発のロボットAI基盤モデルが、オープンソースで世界に公開されたことは、ロボット学習研究のグローバルな加速を予感させる。
コメント