

「開発したものを自ら運用する」──Netflixが実践するフルサイクル開発者の衝撃
「日本にいる一部のエンジニアの方は驚くかもしれませんが、Netflixのプロダクトチームのエンジニアは『開発したものを自ら運用する』という考えで働いています」──こう語るのは、エンジニア面接対策プラットフォーム「InterviewCat」公式アカウント(@InterviewCat582)です。
従来の日本企業では「開発チームが作って、運用チームが動かす」という分業体制が一般的でした。しかし、Netflixはこの常識を覆し、 「You Build It, You Run It(あなたが作ったものは、あなたが運用する)」という哲学を実践しています。
日本にいる一部のエンジニアの方は驚くかもしれませんが、Netflixのプロダクトチームのエンジニアは「開発したものを自ら運用する」という考えで働いています。
— InterviewCat公式@エンジニア面接対策 (@InterviewCat582) October 21, 2025
従来のように開発と運用が分かれていると、知識の断絶やコミュニケーションコストが発生し、障害対応や改善のスピードが落ちてしまいます。
この投稿は65,457回閲覧され、415いいね、289ブックマークを獲得しました。多くの日本のエンジニアが「これが本当のDevOpsか」と衝撃を受けた証拠です。
本記事では、Netflixのフルサイクル開発者(Full Cycle Developers)の全貌と、それを支えるPlatform Engineeringの仕組み、そして日本企業の最新事例を徹底解説します。
従来の「開発と運用の分離」が生む3つの致命的な問題
Netflixがフルサイクル開発者モデルを採用した背景には、従来の分業体制が抱える深刻な問題がありました。
問題1:知識の断絶(Knowledge Gap)
従来の体制では、開発チームと運用チームの間に「知識の壁」が存在します。
開発チームの視点:
- 「このコードがなぜ遅いのか、運用チームに聞かないとわからない」
- 「本番環境でどう動いているかリアルタイムで見れない」
- 「障害が起きても、自分たちで原因特定できない」
運用チームの視点:
- 「このシステムの設計思想がわからない」
- 「なぜこのアーキテクチャなのか開発チームに聞かないとわからない」
- 「改善提案しても、開発チームの優先度が低い」
この断絶により、 障害発生から原因特定まで数時間~数日かかるという事態が発生します。Netflixのような24時間365日稼働するサービスでは、これは致命的です。
問題2:コミュニケーションコスト(Communication Overhead)
開発と運用が分離していると、以下のようなコミュニケーションコストが発生します:
| フェーズ | コミュニケーション内容 | 時間 |
|---|---|---|
| リリース準備 | 運用チームへの事前説明、手順書作成 | 2-4時間 |
| 障害発生 | 開発チームへの連絡、状況説明、調査依頼 | 30分-2時間 |
| 改善提案 | 運用側の要望を開発側に伝える、優先度調整 | 1-3日 |
| パフォーマンス調査 | ログ確認依頼、データ分析の依頼と結果待ち | 1-5日 |
Netflixの元エンジニアによると、「従来の体制では、エンジニアの 時間の30-40%がコミュニケーションコストに消費されていた」と証言しています。
問題3:改善サイクルの鈍化(Slow Feedback Loop)
開発と運用が分離していると、 フィードバックループが非常に遅くなります。
従来の改善サイクル:
- 運用チームが問題を発見(1日)
- 開発チームに報告・説明(1-2日)
- 開発チームが優先度を判断(3-5日)
- 修正の実装(1-2週間)
- テスト(3-5日)
- 運用チームへのリリース依頼(1日)
- 本番デプロイ(1-3日)
合計:3-5週間
一方、フルサイクル開発者モデルでは:
- 開発者自身が問題を発見(リアルタイム)
- 優先度判断(即座)
- 修正実装(数時間~1日)
- テスト(数時間)
- デプロイ(数分)
合計:1-2日
スピードは 10-25倍に向上します。
Netflixのフルサイクル開発者(Full Cycle Developers)とは何か
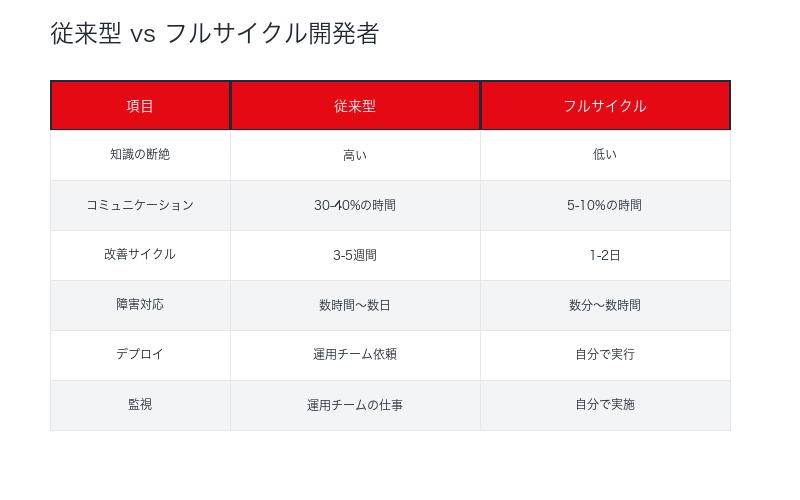
Netflixのフルサイクル開発者は、 ソフトウェアライフサイクルの全工程に責任を持つエンジニアです。
フルサイクル開発者の責任範囲
| フェーズ | 従来の開発者 | フルサイクル開発者 |
|---|---|---|
| 設計 | ✓ 担当 | ✓ 担当 |
| 実装 | ✓ 担当 | ✓ 担当 |
| テスト | △ 一部担当 | ✓ 全て担当 |
| デプロイ | ✗ 運用チームに依頼 | ✓ 自分で実行 |
| 監視 | ✗ 運用チームの仕事 | ✓ 自分で実施 |
| 障害対応 | ✗ 運用チームから連絡を待つ | ✓ 第一対応者 |
| パフォーマンス最適化 | △ 運用チームからの依頼ベース | ✓ 能動的に実施 |
| セキュリティ | △ セキュリティチームに依頼 | ✓ 基本的な対策は自分で |
フルサイクル開発者の1日の仕事
Netflix Edge Engineeringチームのエンジニアの典型的な1日:
午前:
- 9:00 – モニタリングダッシュボードで前日のメトリクス確認
- 9:30 – 新機能の実装(コーディング)
- 11:00 – 自動テストの作成と実行
午後:
- 13:00 – Spinnakerで本番環境にデプロイ
- 13:30 – Atlasでデプロイ後のメトリクス監視
- 14:00 – パフォーマンス異常を検知、調査開始
- 15:00 – 修正コードを実装し、再デプロイ
- 16:00 – チームミーティングで知見を共有
夜間:
- オンコール担当の場合、PagerDutyでアラート受信
- 障害発生時は自分で調査・修正・デプロイ
重要なのは、 「誰かに依頼する」というステップがゼロだという点です。全て自分で完結できます。
ゼロテストチーム、ゼロ運用チーム
Netflixの衝撃的な事実は、 Edge Engineeringチームには専任のテストチームも運用チームも存在しないということです。
Netflix Tech Blogより:
「Edge Engineering has zero test teams and zero dedicated operations teams. Mission critical services are owned and operated by small teams of developers with no dedicated test teams and no dedicated operations teams.」
では、品質はどうやって担保しているのか?
答え:自動化とツールです。
Platform Engineeringが実現する「認知負荷の削減」
ここで疑問が生まれます:「エンジニアが設計から運用まで全てやるなら、認知負荷が高すぎて破綻するのでは?」
その答えがPlatform Engineeringです。
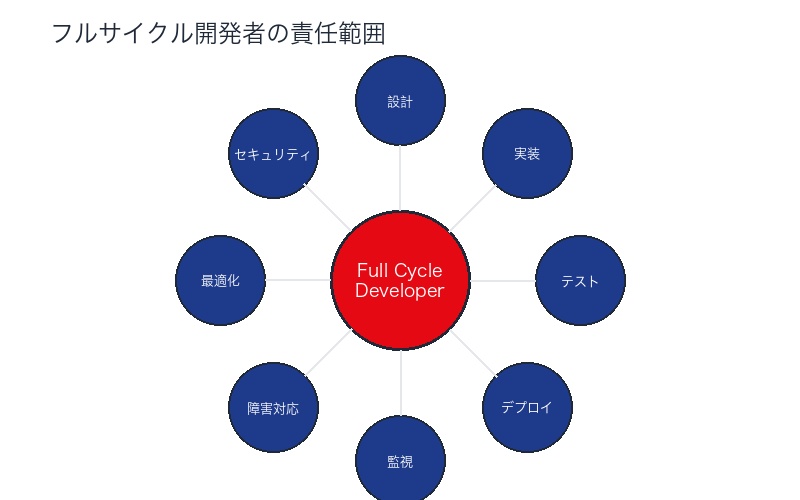
Platform Engineeringとは何か
Platform Engineeringとは、 スペシャリストが開発したツール群をプロダクトチームが利用することで、技術の認知負荷を下げる取り組みです。
InterviewCat公式の投稿にもある通り:
「スペシャリストが開発したツール群をプロダクトチームが利用することで、技術の認知負荷を下げており、全てに詳しくなくとも質の高いサービス開発運用ができるようになっています。」
Netflixのセルフサービスツール群
Netflixがフルサイクル開発者に提供しているツール:
| ツール | 用途 | 削減される認知負荷 |
|---|---|---|
| Spinnaker | デプロイメント自動化 | Kubernetes、AWS ECS、Lambda等の知識不要 |
| Atlas | 監視・メトリクス | Prometheus、Grafanaの設定不要 |
| PagerDuty | アラート・オンコール管理 | 複雑なアラートロジック設定不要 |
| Chaos Monkey | カオスエンジニアリング | 障害シミュレーションの自動化 |
| Hystrix | サーキットブレーカー | 耐障害性の実装が簡単 |
認知負荷削減の具体例:デプロイ
Platform Engineering導入前(従来):
# エンジニアが手動で設定
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-service
spec:
replicas: 3
template:
spec:
containers:
- name: app
image: my-service:v1.2.3
resources:
limits:
cpu: "1000m"
memory: "2Gi"
# ... さらに100行以上の設定エンジニアは以下を理解する必要がありました:
- Kubernetesの詳細仕様
- リソース制限の適切な値
- ネットワーク設定
- セキュリティポリシー
- ロードバランサー設定
Platform Engineering導入後(Spinnaker使用):
# ワンコマンドでデプロイ
spin pipeline execute \
--application my-service \
--name deploy-to-prod \
--parameters version=v1.2.3エンジニアが知る必要があるのは:
- アプリケーション名
- パイプライン名
- バージョン番号
認知負荷は95%削減されました。
「Golden Path」の提供
Platform Engineeringのもう一つの重要な概念が「Golden Path(黄金の道)」です。
これは、 「ほとんどのユースケースで推奨される最適なやり方」を事前に用意しておくという考え方です。
例:
- デプロイ:Spinnakerのテンプレートパイプラインを使えば、カスタマイズ不要で本番デプロイ可能
- 監視:Atlasのデフォルトダッシュボードで、重要なメトリクスは自動表示
- アラート:PagerDutyのテンプレートルールで、適切なエスカレーションが自動設定
開発者は「Golden Pathに従うだけ」で、ベストプラクティスに沿った運用ができます。
日本企業のPlatform Engineering実践事例──LegalOn、サイバーエージェント、LINEヤフー
InterviewCat公式の投稿にもある通り、「日本でもPlatform Engineeringはここ数年で加熱しており、LegalOn Technologies、サイバーエージェント、LINEヤフーなど様々な企業はこの方針を取り入れています」。
事例1:LegalOn Technologies – Akuparaプラットフォーム
LegalOn Technologiesは、2025年のPlatform Engineering Kaigi 2025で大規模プラットフォーム移行戦略を発表しました。
背景:
- 50以上のサービスを運用
- 従来は各チームが独自にインフラ構築
- 知識の属人化、セキュリティリスクの増大
Akuparaプラットフォームの特徴:
- 1日で開発開始:新しいサービスを1日で立ち上げられるテンプレート
- 1ヶ月で必要なインフラ構築:データベース、認証、監視等を自動セットアップ
- マルチリージョン対応:グローバル展開を見据えた設計
移行期間:
- 2024年7月開始 → 2025年7月正式リリース
- 約1年で50+サービスの移行完了
成果:
- 新サービス立ち上げ時間:2週間 → 1日(14倍高速化)
- インフラ構築時間:3ヶ月 → 1ヶ月(3倍高速化)
- セキュリティインシデント:大幅減少
事例2:サイバーエージェント – AKE(マネージドKubernetes)
サイバーエージェントは、社内共通プラットフォームとして「AKE(Ake)」を提供しています。
AKEの特徴:
- KaaS(Kubernetes as a Service):社内向けマネージドKubernetes
- 63個のGatekeeperポリシー:Kubernetesのベストプラクティスを自動適用
- 余剰リソース検出機能:コスト最適化を自動提案
- 非推奨API通知:Kubernetes更新時の互換性問題を事前警告
導入効果:
- Kubernetes学習コスト:大幅削減
- セキュリティポリシー遵守率:100%
- インフラコスト:20-30%削減
事例3:LINEヤフー – 大規模Webアプリケーションプラットフォーム
LINEヤフーの早川浩氏は、Platform Engineering Meetup #6で大規模Webアプリケーションプラットフォームの開発・運用について講演しました。
取り組み内容:
- ローンチから安定運用までの「地道な活動」
- 開発者体験(Developer Experience, DX)の向上
- 複数サービスの統合基盤構築
重視したポイント:
- 段階的な移行:一度に全てを変えず、小さく始めて徐々に拡大
- 開発者との対話:ツールを押し付けるのではなく、ニーズを聞いて改善
- ドキュメント整備:Golden Pathを明文化し、誰でも使えるように
日本企業が直面する課題
日本企業がPlatform Engineeringを導入する際の共通課題:
| 課題 | 対策 |
|---|---|
| 既存システムの複雑性 | 段階的移行、共存期間の設定 |
| エンジニアの抵抗感 | 成功事例の共有、トレーニング実施 |
| Platform Engineeringチームの人材不足 | 外部コンサル活用、SREからの配置転換 |
| ROIの測定難 | 開発速度、障害率、コストを定量化 |

フルサイクル開発者になるために必要なスキルセット
では、フルサイクル開発者になるには何が必要なのでしょうか?
技術スキル
必須スキル:
- プログラミング:言語は問わないが、深い理解が必要
- テスト:ユニットテスト、統合テスト、E2Eテストの実装
- デプロイ:CI/CDパイプラインの理解と利用
- 監視:メトリクス、ログ、トレーシングの読み方
- 障害対応:ログ解析、デバッグ、ロールバック手順
推奨スキル:
- インフラ:Kubernetes、AWS/GCP/Azure の基礎知識
- ネットワーク:HTTP、TCP/IP、DNS、ロードバランサー
- セキュリティ:OWASP Top 10、認証・認可の基本
- データベース:SQL、インデックス、クエリ最適化
マインドセット
技術スキル以上に重要なのがマインドセットです。
「問題を自分で解決する」姿勢:
- 「誰かに聞く」前に「自分で調べる」
- 「これは運用チームの仕事」と思わない
- 「自分のコードは自分で責任を持つ」
「自動化ファースト」の考え方:
- 「手動でやる」ではなく「どう自動化するか」を考える
- 「同じことを2回やるなら、スクリプトを書く」
- 「セルフサービスツールで解決できないか」を常に考える
「継続的学習」の習慣:
- 新しいツールや技術を学び続ける
- 他チームの知見を積極的に取り入れる
- 失敗から学び、ポストモーテムを共有する
Netflixの育成プログラム
Netflixは、フルサイクル開発者を育成するために以下のプログラムを提供しています:
1. Dev Bootcamp(開発者ブートキャンプ)
- 期間:2-4週間
- 内容:Spinnaker、Atlas、PagerDutyなどのツール実践
- 対象:新入社員、既存エンジニアのスキルアップ
2. On-the-Job Training(OJT)
- 先輩エンジニアとペアプログラミング
- 障害対応のシャドウイング
- オンコール当番の段階的導入
3. Continuous Learning(継続的学習)
- 社内勉強会・Tech Talks
- 外部カンファレンス参加支援
- オンラインコース受講補助
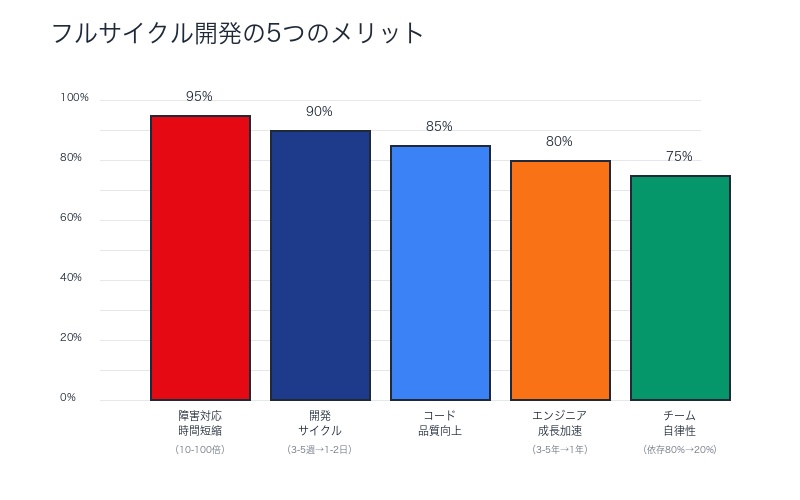
フルサイクル開発とPlatform Engineeringがもたらす5つのメリット
メリット1:障害対応時間の劇的短縮
従来:
- 障害発生 → 運用チームが検知 → 開発チームに連絡 → 調査 → 修正 → テスト → デプロイ
- 合計:数時間~数日
フルサイクル開発:
- 障害発生 → 開発者が検知 → 調査 → 修正 → デプロイ
- 合計:数分~数時間
改善率:10-100倍高速化
メリット2:開発速度の向上
- コミュニケーションコスト削減:30-40% → 5-10%
- 待ち時間ゼロ:「運用チームの対応待ち」がなくなる
- フィードバックループ高速化:3-5週間 → 1-2日
メリット3:コードの品質向上
「自分で運用する」ことで、エンジニアは以下を意識するようになります:
- 可観測性(Observability):適切なログ、メトリクス、トレーシングを最初から実装
- エラーハンドリング:運用で困らないよう、エラー処理を丁寧に書く
- パフォーマンス:遅延が発生しないよう、最初から最適化を意識
- セキュリティ:脆弱性が運用トラブルに直結するため、慎重に実装
メリット4:エンジニアの成長加速
フルサイクル開発者は、以下を経験できます:
- 本番環境での学び:実際のユーザー行動、トラフィックパターン
- 障害対応の経験:プレッシャーの中での問題解決
- 幅広い技術知識:開発だけでなく、インフラ、ネットワーク、セキュリティ
Netflix元エンジニアの証言:「1年間のフルサイクル開発経験は、従来の3-5年分の成長に相当する」
メリット5:チームの自律性向上
- 外部チームへの依存度低下:80% → 20%
- 意思決定の高速化:承認プロセスが不要
- イノベーションの促進:試行錯誤のコストが下がる
導入の課題と解決策──「いきなり全部」は失敗する
フルサイクル開発とPlatform Engineeringは魅力的ですが、導入には課題があります。
課題1:エンジニアの認知負荷過多
問題:
- 「開発だけでも忙しいのに、運用まで担当できない」
- 「全ての技術を学ぶ時間がない」
解決策:
- Platform Engineeringで負荷削減:Golden Pathを提供し、選択肢を減らす
- 段階的導入:最初は監視だけ、次にデプロイ、最後に障害対応
- ペアプログラミング:経験者と一緒に実施して学ぶ
課題2:Platform Engineeringチームの構築
問題:
- 「誰がPlatform Engineeringチームを作るのか」
- 「そもそもスペシャリストがいない」
解決策:
- SREチームの転換:既存のSREチームをPlatform Engineeringチームに再編
- 外部ツールの活用:最初はOSS(Spinnaker、Argo CD等)を導入
- 段階的な内製化:最初は外部ツール、徐々に自社開発ツールに置き換え
課題3:文化の変革
問題:
- 「これまで運用チームがやっていたのに、なぜ開発者が?」
- 「責任範囲が広がりすぎて不安」
解決策:
- 経営層のコミットメント:トップダウンで方針を明確化
- 成功事例の共有:小規模チームで試して成果を見せる
- インセンティブ設計:評価制度にフルサイクル開発の実績を組み込む
推奨:段階的導入ロードマップ
フェーズ1(0-3ヶ月):基盤整備
- Platform Engineeringチーム立ち上げ
- OSSツール(Spinnaker、Prometheus等)の導入
- パイロットチーム選定
フェーズ2(3-6ヶ月):パイロット実施
- 1-2チームでフルサイクル開発試行
- Golden Path整備
- トレーニングプログラム開発
フェーズ3(6-12ヶ月):全社展開
- 成功事例を基に全チームに展開
- 自社開発ツールの追加
- KPI測定と継続改善
まとめ──「You Build It, You Run It」が当たり前の時代へ
Netflixのフルサイクル開発者とPlatform Engineeringは、単なるトレンドではなく、 ソフトウェア開発の新しいスタンダードになりつつあります。
重要ポイントの再確認
1. フルサイクル開発者の定義
- 設計、開発、テスト、デプロイ、運用まで全工程に責任を持つエンジニア
- 「You Build It, You Run It」の哲学を実践
2. Platform Engineeringの役割
- スペシャリストが開発したツール群で認知負荷を削減
- Golden Pathを提供し、ベストプラクティスを標準化
3. 日本企業の動向
- LegalOn Technologies、サイバーエージェント、LINEヤフー等が積極導入
- ここ数年で急速に加熱
4. 主なメリット
- 障害対応時間:10-100倍高速化
- 開発サイクル:3-5週間 → 1-2日
- エンジニアの成長:3-5年 → 1年相当
次のアクション
この記事を読んで「自社でも試したい」と思った方へのアドバイス:
個人として始められること:
- 自分のプロダクトを本番環境まで追いかける習慣をつける
- 監視ダッシュボードを毎朝確認する
- デプロイツール(GitHub Actions、Argo CD等)を学ぶ
チームとして始められること:
- 小規模な新規プロジェクトでフルサイクル開発を試行
- OSSのPlatform Engineeringツールを導入
- 勉強会でNetflixの事例を共有
組織として始められること:
- Platform Engineeringチームの立ち上げ
- SREチームの再編成
- 経営層へのROI提示と予算確保
「開発と運用の断絶」は、もはや過去の遺物です。フルサイクル開発者とPlatform Engineeringで、あなたの組織も変革の一歩を踏み出してみませんか?
コメント