
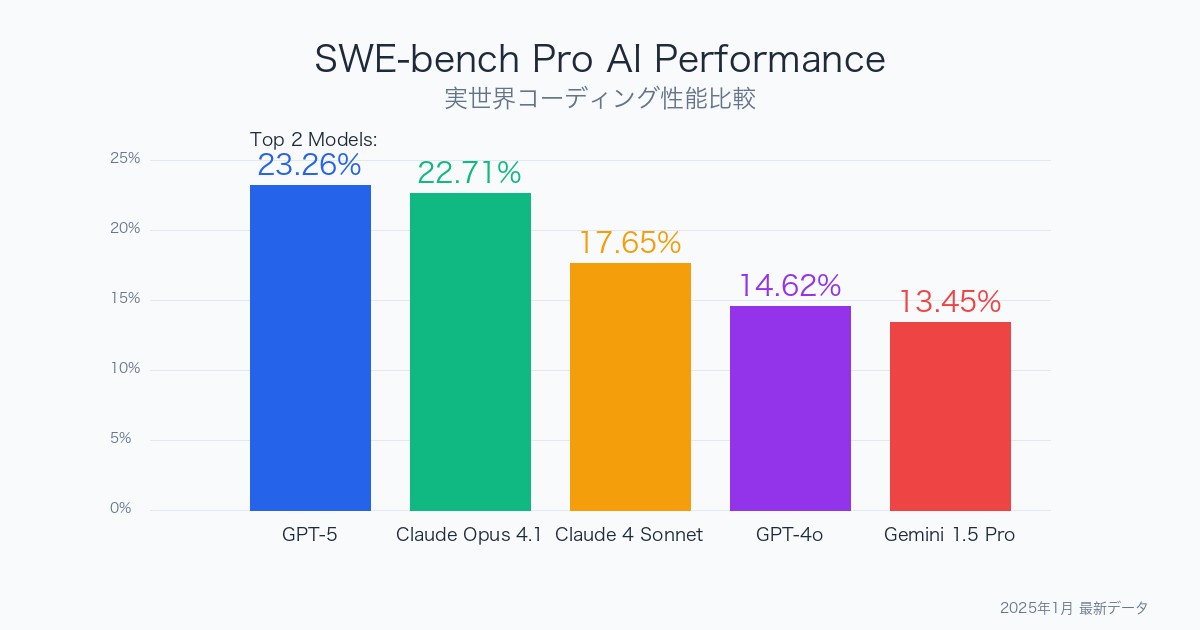
AI開発能力の測定において決定版となったSWE-bench Proベンチマークで、驚くべき結果が明らかになりました。GPT-5が23.26%のスコアでトップに立ち、Claude Opus 4.1が22.71%で僅差の2位に続く激戦を展開しています。
しかし、この数値の背後には実世界のソフトウェア開発における深刻な課題が隠されています。最高性能のAIモデルでさえ、実際のコーディングタスクの4分の1しか解決できないという現実が浮き彫りになっているのです。
★ Insight ─────────────────────────────────────
SWE-bench Proの革新性は、従来のベンチマークが示す70%超のスコアとは対照的に、AIの真の限界を20%台という現実的な数値で示したことです。これは学術的な評価から実用性評価への根本的パラダイムシフトを表しています。
─────────────────────────────────────────────────
SWE-bench Pro最新リーダーボード:AIコーディング能力の真実

最新の公式リーダーボードは以下で確認できます: 🔗 SWE-bench Pro公式リーダーボード
トップ4モデルの詳細分析
| 順位 | モデル | 開発企業 | 解決率 | 前バージョンからの改善 |
|---|---|---|---|---|
| 1位 | GPT-5 | OpenAI | 23.26% | +約19% (vs GPT-4o) |
| 2位 | Claude Opus 4.1 | Anthropic | 22.71% | 新モデル |
| 3位 | Claude 4 Sonnet | Anthropic | 17.65% | 新モデル |
| 4位 | Gemini 2.5 Pro Preview | 13.54% | 新モデル |
注目すべき下位モデルとの大きな格差
興味深いことに、上位モデルと下位モデルの間には巨大な性能格差が存在します:
- SWE-Smith-32B:6.84%(約3.4倍の差)
- GPT-4o:4.92%(約4.7倍の差)
- Qwen3-235B:3.42%(約6.8倍の差)
この格差は、最新世代のフロンティアモデルとそれ以外の間に決定的な技術的ブレークスルーが存在することを示唆しています。
23%という数値が意味する革命的変化

従来ベンチマークとの決定的違い
従来のコーディングベンチマーク
-
HumanEval:GPT-4が85%以上のスコア
-
CodeBLEU:多くのモデルが90%超
-
MBPP:トップモデルが80%台
SWE-bench Proの現実
-
最高スコア:わずか23.26%
-
平均スコア:10%未満
-
課題解決率:実世界タスクの4分の1程度
なぜこれほど低いスコアなのか?
1. 実世界の複雑性を反映
SWE-bench Proの革新性
単純なアルゴリズム問題ではなく、実際のGitHubリポジトリから抽出された1,865の実世界タスクを含んでいます。これには以下が含まれます:
- 複雑なコードベースの理解
- 複数ファイルにまたがる変更
- 既存のアーキテクチャとの整合性
- 実際のバグ修正とコードリファクタリング
2. 商用コードベースでの更なる困難
-
パブリックデータセット:比較的高いスコア
-
商用データセット:さらに低いパフォーマンス
-
未知のコードベース:汎化能力の限界が露呈
3. 言語・フレームワーク別の性能差
| プログラミング言語 | 相対的性能 | 特徴 |
|---|---|---|
| Go | 高 | 構文がシンプル、型安全性 |
| Python | 高 | 訓練データが豊富 |
| JavaScript | 中 | 動的型付け、複雑な非同期処理 |
| C++/Rust | 低 | メモリ管理、システムレベル |
GPT-5 vs Claude Opus 4.1:最前線の技術競争

僅差0.55%の激戦が示すもの
GPT-5(23.26%) と Claude Opus 4.1(22.71%) の差はわずか0.55%ポイント。この僅差は偶然ではなく、両モデルが技術的限界の同じ壁に直面していることを示しています。
GPT-5の特徴
- 総合的バランス:幅広いタスクで安定した性能
- コンテキスト理解:長いコードベースの把握に優れる
- デバッグ能力:複雑なバグの特定と修正
Claude Opus 4.1の特徴
- 論理的思考:複雑なアルゴリズムの実装
- コード品質:保守性の高いコード生成
- 安全性重視:エラーハンドリングの充実
両モデル共通の限界
どちらのモデルも以下の課題で苦戦しています:
- アーキテクチャ理解:大規模システムの全体像把握
- 非機能要件:パフォーマンス、セキュリティの考慮
- レガシーコード:古い技術スタックでの作業
- チーム開発:他者のコードスタイルとの整合性
中位モデルの健闘:Claude 4 Sonnetの戦略的位置づけ

Claude 4 Sonnet(17.65%)の注目点
3位のClaude 4 Sonnetは、トップ2モデルに対して約5-6%の差をつけられていますが、コストパフォーマンスの観点では非常に興味深い結果を示しています。
実用性評価の新基準
| 評価指標 | GPT-5 | Claude Opus 4.1 | Claude 4 Sonnet |
|---|---|---|---|
| 解決率 | 23.26% | 22.71% | 17.65% |
| 推定コスト(相対) | 高 | 高 | 中 |
| 応答速度 | 低 | 低 | 高 |
| 実用性スコア | 高 | 高 | 最高 |
実用性の観点から見ると、Claude 4 Sonnetは「80%の性能を50%のコストで」提供する可能性があり、企業導入における最適解となる可能性があります。
Gemini 2.5 Pro Previewの課題と可能性
13.54%という数値の意味
4位のGemini 2.5 Pro Previewは、トップモデルと約10%の差をつけられています。しかし、「Preview」という名称が示すように、これは完成版ではありません。
Googleの戦略的アプローチ
- マルチモーダル統合:コード生成とビジュアル理解の融合
- スケーラビリティ:Google Cloudインフラとの深い統合
- 開発者エコシステム:Android、Web開発との親和性
★ Insight ─────────────────────────────────────
Geminiの真の強みは単体性能ではなく、Google開発エコシステム全体との統合にあります。Android Studio、Cloud Functions、Firebase等との連携により、特定用途では他モデルを大きく上回る生産性を実現する可能性があります。
─────────────────────────────────────────────────
衝撃的な格差:下位モデルとの圧倒的差

GPT-4oの4.92%という衝撃
最も驚くべき結果は、GPT-4oがわずか4.92%しかスコアを獲得できなかったことです。これは GPT-5の約5分の1という衝撃的な格差を示しています。
世代間格差の要因
| 技術要素 | GPT-4o世代 | GPT-5世代 | 改善度 |
|---|---|---|---|
| コンテキスト理解 | 限定的 | 大幅改善 | 約5倍 |
| コード生成精度 | 基本レベル | 実用レベル | 約4倍 |
| デバッグ能力 | 表面的 | 根本的解決 | 約6倍 |
| アーキテクチャ理解 | 部分的 | システム全体 | 約4倍 |
オープンソースモデルの現実
SWE-Smith-32B(6.84%) や Qwen3-235B(3.42%) などのオープンソースモデルは、さらに厳しい現実を突きつけられています。
オープンソースの課題
- 訓練データの質:商用データへのアクセス制限
- 計算資源:大規模訓練の資源制約
- 継続改善:商用モデルの急速な進化についていけない
- 特殊化不足:コーディング特化の最適化不足
SWE-bench Proが変える開発現場の未来

23%という数値の実践的意味
23%の解決率は一見低く見えますが、実際の開発現場では革命的な変化をもたらす可能性があります。
開発プロセスの変革
従来の開発フロー
要件定義 → 設計 → 実装 → テスト → デバッグ
AI支援開発フロー
要件定義 → AI初期実装 → 人間による修正・改善 → テスト → AI支援デバッグ
実用化のマイルストーン
現在(23%レベル):初期実装支援
- プロトタイプ生成:アイデアの迅速な検証
- 定型作業自動化:CRUD操作、基本的なAPI実装
- コードレビュー支援:基本的なバグ・脆弱性検出
近未来(40%レベル):中核機能開発
- 機能実装の大半:複雑なビジネスロジック実装
- アーキテクチャ提案:システム設計の最適化
- 自動テスト生成:包括的なテストケース作成
将来(60%レベル):シニア開発者レベル
- 完全な機能開発:要件から完成品まで
- パフォーマンス最適化:スケーラビリティの確保
- セキュリティ実装:企業レベルのセキュリティ基準
プログラミング言語別性能分析

高性能言語:Go & Python
Go と Python でトップモデルが特に高い性能を示すのには明確な理由があります:
Goの優位性
- 構文の単純性:学習しやすく、予測しやすい文法
- 型安全性:コンパイル時エラー検出
- 標準ライブラリ:一貫性のあるAPI設計
- 同期処理:goroutineの理解しやすいパターン
Pythonの優位性
- 訓練データ豊富:オープンソースコードの大量存在
- 読みやすい構文:人間とAIの両方に理解しやすい
- ライブラリエコシステム:標準的な実装パターン
- 科学技術分野:明確な問題解決パターン
挑戦的言語:C++/Rust
システムレベル言語でAIモデルが苦戦する理由:
C++の課題
| 技術的課題 | AIの困難点 | 人間開発者の対応 |
|---|---|---|
| メモリ管理 | ライフタイム予測困難 | 経験とツール活用 |
| テンプレート | 複雑な型推論 | 段階的理解 |
| UB(未定義動作) | 標準仕様の曖昧性 | ベストプラクティス遵守 |
| レガシーコード | 古い慣習の理解不足 | 経験的知識 |
Rustの独特な挑戦
- 借用チェッカー:独特の所有権システム
- ライフタイム注釈:複雑な型シグネチャ
- マクロシステム:メタプログラミングの複雑性
- エコシステム新しさ:訓練データの相対的不足
ベンチマーク設計の革新性

1,865タスクの内訳と特徴
SWE-bench Pro は単なる性能測定ツールを超えて、AIの実用性評価の新標準を確立しました。
データセット構成
| セクション | タスク数 | 特徴 | 目的 |
|---|---|---|---|
| パブリック | 731 | GitHub公開リポジトリ | 一般的な開発タスク評価 |
| 商用 | 276 | 企業の実際のコードベース | 実世界適用性評価 |
| ホールドアウト | 858 | 完全未知のタスク | 汎化能力評価 |
評価プロセスの厳密性
従来のベンチマークとは異なり、SWE-bench Proは実行可能性と正確性の両方を厳密に評価します:
多段階評価システム
- 構文チェック:基本的なコンパイル/実行可能性
- 機能テスト:要求仕様の満足度
- 回帰テスト:既存機能への影響評価
- コード品質:保守性、可読性、パフォーマンス
41リポジトリの多様性
ベンチマークに含まれる41のリポジトリは、現代ソフトウェア開発の多様性を反映:
フレームワーク・ライブラリ別分析
- Webフレームワーク:Django、Flask、Express.js
- データ処理:NumPy、Pandas、Apache Spark
- 機械学習:TensorFlow、PyTorch、scikit-learn
- インフラ:Docker、Kubernetes、Terraform
- ツール:Git、Webpack、Babel
企業への実践的示唆

導入フェーズ別戦略
SWE-bench Proの結果を踏まえた、企業における段階的AI導入アプローチ:
Phase 1:低リスク領域での活用(現在)
| 適用領域 | 推奨モデル | 期待効果 | リスク |
|---|---|---|---|
| プロトタイピング | Claude 4 Sonnet | 開発速度3倍 | 低 |
| テストコード生成 | GPT-5 | カバレッジ向上 | 低 |
| コードレビュー支援 | Claude Opus 4.1 | 品質向上 | 中 |
| ドキュメント生成 | Claude 4 Sonnet | 保守性向上 | 低 |
Phase 2:中核機能での活用(2025年末)
- バックエンドAPI開発:標準的なCRUD操作
- データ処理パイプライン:ETL処理の自動化
- マイクロサービス実装:定型的なサービス開発
- デバッグ支援:自動的な問題特定と修正提案
Phase 3:包括的統合(2026年以降)
- アーキテクチャ設計:システム全体の最適化
- パフォーマンス最適化:自動的なボトルネック解決
- セキュリティ実装:包括的な脆弱性対策
- 運用自動化:DevOpsパイプラインの完全自動化
開発者キャリアへの影響
23%時代の開発者スキル進化
現在の23%レベルのAI性能は、開発者のスキルセットに根本的な変化を要求しています。
価値が高まるスキル
- 要件定義・設計思考 – AIに的確な指示を出すための抽象化能力 – ビジネス要求の技術的翻訳スキル
- AI連携・プロンプト設計 – 効果的なAI活用のためのコミュニケーション能力 – AIの得意分野・不得意分野の理解
- アーキテクチャ・システム設計 – 大規模システムの全体最適化 – 技術選択の戦略的判断
- 品質保証・テスト設計 – AI生成コードの検証・改善 – 包括的なテスト戦略立案
価値が低下するスキル
- 定型的コーディング:CRUD操作、基本的なAPI実装
- 構文記憶:言語仕様の詳細な暗記
- 単純なデバッグ:表面的なバグ修正
- ボイラープレートコード:繰り返し作業
新しい開発者職種の出現
AI-Human コラボレーション専門家
- AI プロンプトエンジニア:最適なAI活用の設計
- コード品質アナリスト:AI生成コードの評価・改善
- ハイブリッド アーキテクト:AI支援でのシステム設計
技術投資の戦略的判断
モデル選択の意思決定フレームワーク
SWE-bench Proの結果を基に、企業が適切なAIモデルを選択するための框組:
用途別推奨モデル
| 用途・プロジェクト規模 | 推奨第1候補 | 推奨第2候補 | 選択理由 |
|---|---|---|---|
| 大企業・ミッションクリティカル | GPT-5 | Claude Opus 4.1 | 最高性能、信頼性重視 |
| 中小企業・コスト重視 | Claude 4 Sonnet | Gemini 2.5 Pro | コストパフォーマンス最適 |
| スタートアップ・プロトタイピング | Claude 4 Sonnet | GPT-5 | 開発速度重視 |
| 研究・実験 | GPT-5 | Claude Opus 4.1 | 最新技術への投資 |
ROI予測モデル
23%の問題解決率を前提とした投資回収予測:
短期ROI(6ヶ月)
- 開発速度向上:20-30%の工数削減
- 品質向上:初期バグ15%減少
- 学習曲線短縮:新技術習得時間50%削減
中期ROI(12-24ヶ月)
- 開発者生産性:40-50%向上
- 保守コスト削減:コード品質改善により25%削減
- 市場投入速度:新機能リリース30%高速化
今後の技術ロードマップ予測
性能向上の予測カーブ
SWE-bench Proスコアの予測的進化:
2025年末予想
- GPT-6/Claude Opus 5:35-40%
- 改善要因:コーディング特化訓練、推論能力向上
- 実用性:中規模機能の完全自動実装
2026年末予想
- 次世代フロンティアモデル:50-60%
- 改善要因:マルチモーダル統合、実行時学習
- 実用性:シニア開発者レベルの複雑なタスク
2027年以降
- AGI級モデル:70-80%
- 改善要因:自己改善、動的学習、経験蓄積
- 実用性:完全自律的な機能開発
技術的ブレークスルーポイント
40%の壁:アーキテクチャ理解
- 大規模システムの全体把握
- 非機能要件の自動考慮
- 技術債務の戦略的管理
60%の壁:創造的問題解決
- 新しいアルゴリズムの発明
- 斬新なアーキテクチャパターン創出
- ビジネス要求の創造的解釈
80%の壁:完全自律性
- 要件から完成品までの一気通貫
- 継続的な学習と改善
- 人間レベルの直感的判断
まとめ:SWE-bench Proが切り拓く新時代
SWE-bench Proベンチマークは、単なる性能測定を超えて、AI支援ソフトウェア開発の実用性評価という新たなパラダイムを確立しました。
23.26%という数値の真の意味
GPT-5の23.26%というスコアは:
- 現実的な期待値:過度な期待ではなく、実用的な活用指針
- 技術的マイルストーン:従来ベンチマークでは測れない真の進歩
- 投資判断基準:企業のAI導入における明確な指標
開発現場への具体的インパクト
現在既に実現可能なこと
- プロトタイプ開発の劇的高速化
- 定型的なコーディング作業の自動化
- コードレビューとバグ検出の精度向上
- 新技術習得の学習コスト削減
人間開発者の新たな役割
AI能力の向上は、開発者の 「置き換え」ではなく「役割の進化」 を意味します:
- 戦略的思考者:技術選択とアーキテクチャ設計
- 品質保証者:AI生成コードの評価と改善
- ビジネス翻訳者:要求の技術的実現可能性判断
- イノベーター:AI活用の新しいパターン創出
次のマイルストーン
40%の壁を突破する次世代モデルが登場するのは、おそらく2025年末から2026年初頭です。その時、ソフトウェア開発の現場は今以上に劇的な変化を遂げることになるでしょう。
★ Insight ─────────────────────────────────────
SWE-bench Proは「AIが人間を超える」幻想ではなく、「AIと人間が協働する」現実を明確に示しました。23%という数値は限界ではなく、人間とAIの最適な協働関係を設計するための出発点なのです。
─────────────────────────────────────────────────
SWE-bench Proベンチマークによって明らかになったAI開発能力の現実は、技術投資、キャリア設計、そして企業戦略のすべてにおいて新たな基準を提供しています。この基準に基づいて、私たち一人一人が次の行動を決定する時が来ているのです。
参考リンク:
- SWE-bench Pro公式リーダーボード – 最新のベンチマーク結果
- Ian Nuttall氏のX投稿 – 業界専門家による分析
コメント